
I would love to only develop streaming pipelines but in reality some of them are still batch oriented. Today you will learn how to properly configure Google Cloud Platform scheduler – Cloud Composer.
The article is for Cloud Composer version 1.x only.
Why not use version 2.x? It’s a good question, indeed.
But the reality of real life has forced me to tune to the obsolete version.
Overview
Cloud Composer is a fully managed workflow orchestration service built on Apache Airflow. Cloud Composer is a magnitude easier to set up than vanilla Apache Airflow, but there are still some gotchas:
- How many resources are allocated by the single Apache Airflow task?
- How many concurrent tasks can be executed on the worker, what’s a real worker capacity?
- What’s a total parallelism of the whole Cloud Composer cluster?
- How to choose the right virtual machine type and how to configure Apache Airflow to fully utilize the allocated resources?
- What are the most important Cloud Composer performance metrics to monitor?
Tasks
Let’s begin with the Apache Airflow basic unit of work - task. There are two main kind of tasks: operators and sensors. In my Cloud Composer installation operators are mainly responsible for creating the ephemeral Dataproc clusters and submit Apache Spark batch jobs to this clusters. In contrast, the sensors wait for BigQuery data, the payload for the Spark jobs. From the performance perspective, the operators are much more resource heavy than sensors.
BigQuery sensors are short-lived tasks if configured in the rescheduling mode The sensor checks for the data and if data exists the sensor quickly finishes. If data isn’t available yet, the sensor finishes as well, but it’s also rescheduled for the next execution after poke_interval.
On the contrary Spark operator allocates resources for the whole Spark job’s execution time. It could take several minutes or even hours. For most of the time, the operator doesn’t do much more than checking for the Spark job status, so it’s a memory bound process. Even if there is a CPU time slots shortage on the Cloud Composer worker, the negative impact on the Spark job itself is negligible.
So for further capacity planning we should mainly count memory allocated by operators and add some safety margin for the sensors.
How to check how much memory is allocated by the operators? It’s not an easy task, Cloud Composer workers form a Kubernetes cluster. You could try to connect to the Kubernetes airflow-worker pod or … run a dozen of tasks and measure the real resource utilization. I would opt for the second, more practical option.
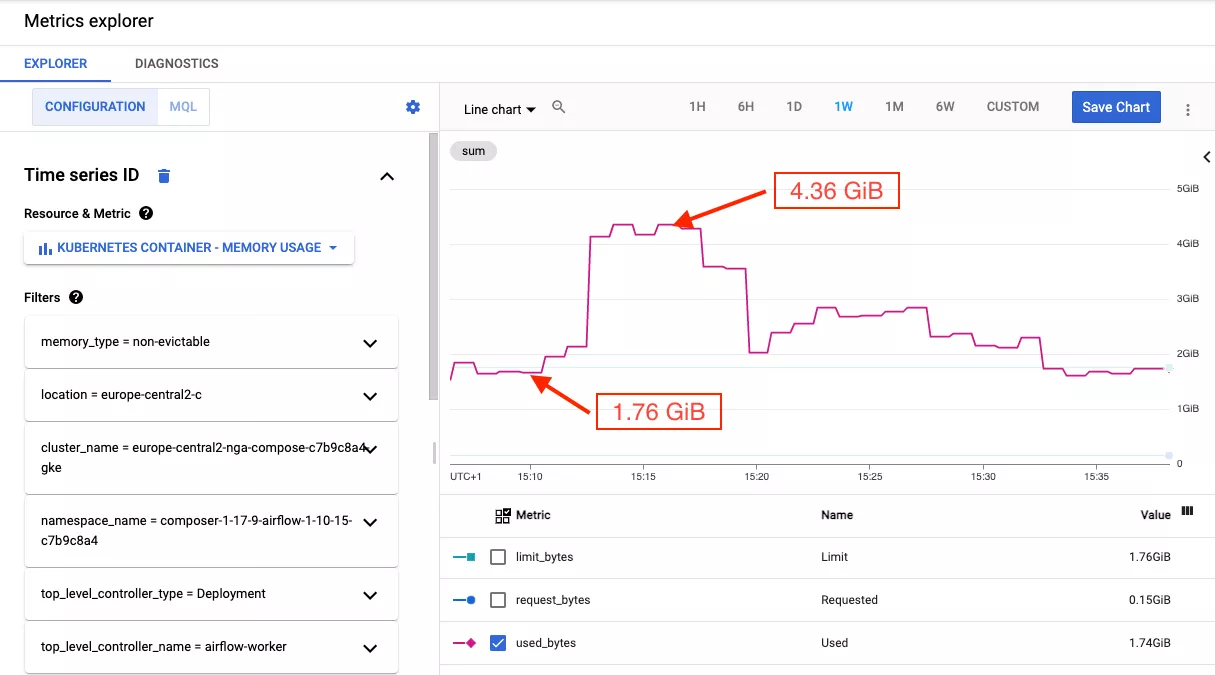
For 12 concurrent running operators the workers’ memory utilization increased from the steady state of 1.76GiB to 4.36GiB.
We do have the first insight in our tuning journey: every operator allocates approximately (4.36GiB - 1.76GiB) / 12 =~ 220MiB of RAM.
It’s important that you should measure the task memory usage by yourself, all further calculations heavily depend on it.
The memory usage might be also varying for different Apache Airflow operators.
Whaaaat – 220MiB allocated just for the REST call to the Dataproc cluster API? Unfortunately it isn’t only the remote call. The architecture of the Apache Airflow is quite complex, every task is executed as a Celery worker with its own overhead. Every task also needs a connection to the Apache Airflow database, it also consumes resources. Perhaps there are other factors I’m not even aware of …
Worker Size
We already know the memory utilization of the single task. Let’s find out how many tasks can be executed concurrently on the worker. It depends on:
- The type of Apache Airflow task
- Allocatable memory on Kubernetes cluster
- Cloud Composer built-in processes overhead
- The type of the virtual machine, finally
Allocatable memory on Kubernetes
The allocatable memory on Kubernetes cluster is calculated in the following way:
Capacity - 25%for the first 4GiBCapacity - 20%for the next 4GiB (up to 8GiB)Capacity - 10%for the next 8GiB (up to 16GiB)
So, for the standard virtual machines, allocatable memory should be as follows:
| Worker | Formula | Allocatable Memory |
|---|---|---|
| n1-standard-1 | 3.75GiB - 25% | 2.8GiB |
| n2-standard-2 | (4GiB - 25%) + (4GiB - 20%) | 6.2GiB |
| n2-highmem-2 | 6.2GiB + (8GiB - 10%) | 13.4GiB |
How does it look in practice? It’s always worth checking because the real allocatable memory is a bit lower than in the calculations.
n1-standard-1 virtual machines: 2.75GB (2.56GiB)
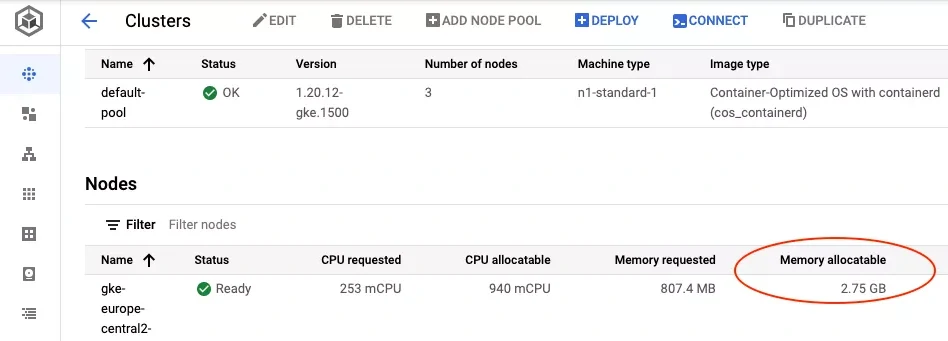
n2-standard-2 virtual machines: 6.34GB (5.9GiB)
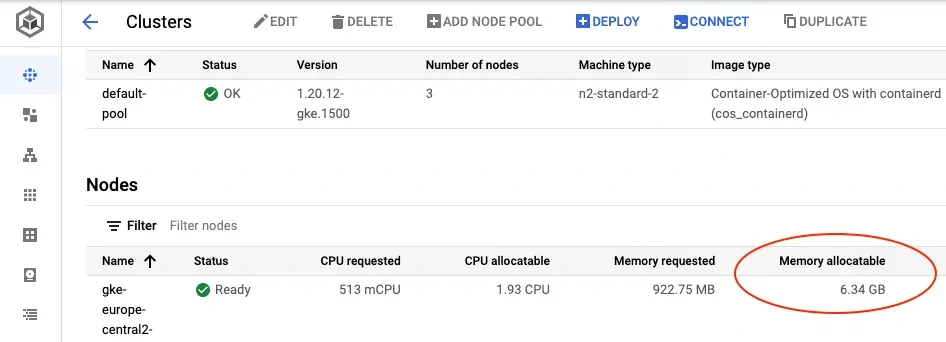
Thank you, Google, for using different units across the console. An intellectual challenge every time when I have to convert GB to GiB and vice-versa.
The costs
The minimal Cloud Composer cluster has to consist of at least three workers. But the workers are only a part of total Cloud Composer costs. Below you can find the estimated monthly costs for 3-nodes Cloud Composer installation in eu-west1 region. As you can see, for larger workers you will get more compute power for just a little more money.
| Worker | CPUs | MEM | Estimated monthly cost |
|---|---|---|---|
| n1-standard-1 | 1 | 3.75GiB | ~ $410 |
| n2-standard-2 | 2 | 8GiB | ~ $510 |
| n2-highmem-2 | 2 | 16GB | ~ $570 |
Based on my experiences, real costs are ~20% higher than presented numbers.
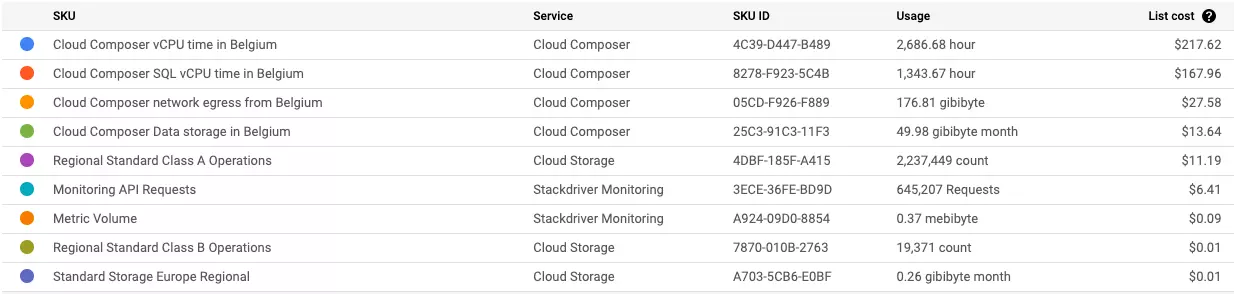
The monthly costs report for n1-standard-1 cluster which was doing literally nothing. Total of $444 for the short February, but please keep in mind that my company has negotiated some discounts already applied in the report. So for the standard customers the costs will be even higher.
Cloud Composer overhead
Kubernetes isn’t the only overhead you have to count into the calculations. There are also many built-in Cloud Composer processes run on every worker. Because the Cloud Composer is a managed service, you don’t have control over these processes. Or even if you know how to hack some of them, you shouldn’t - the future upgrades or the troubleshooting would be a bumpy walk.
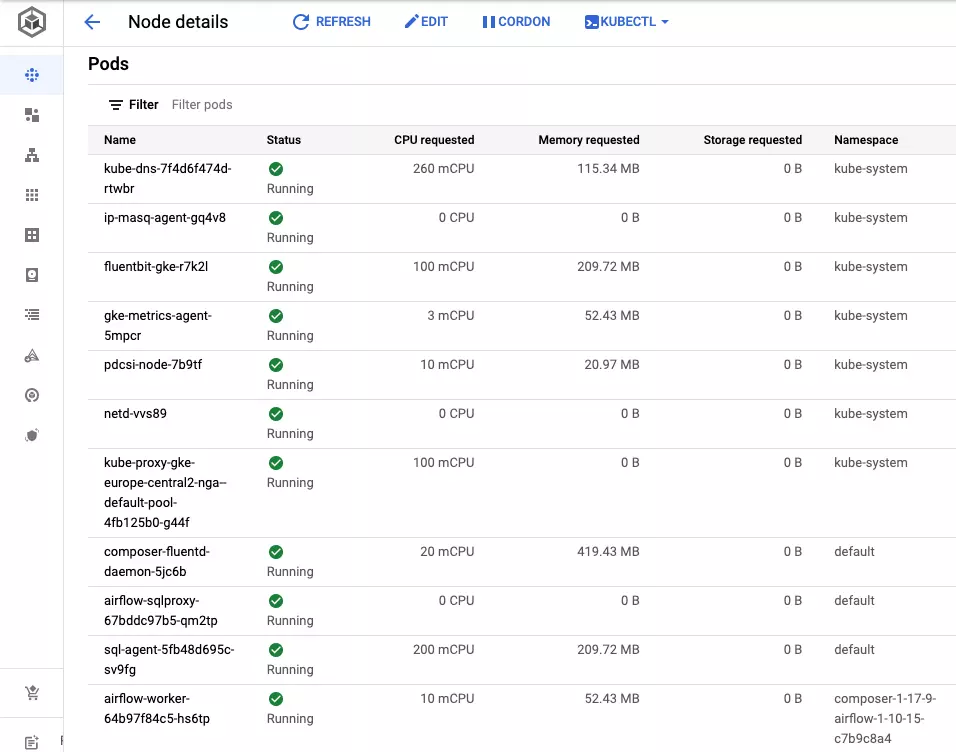
Don’t rely on the reported requested memory, it’s just garbage. Just measure the maximum worker memory utilization on the clean Cloud Composer installation and add the result to the final estimate.
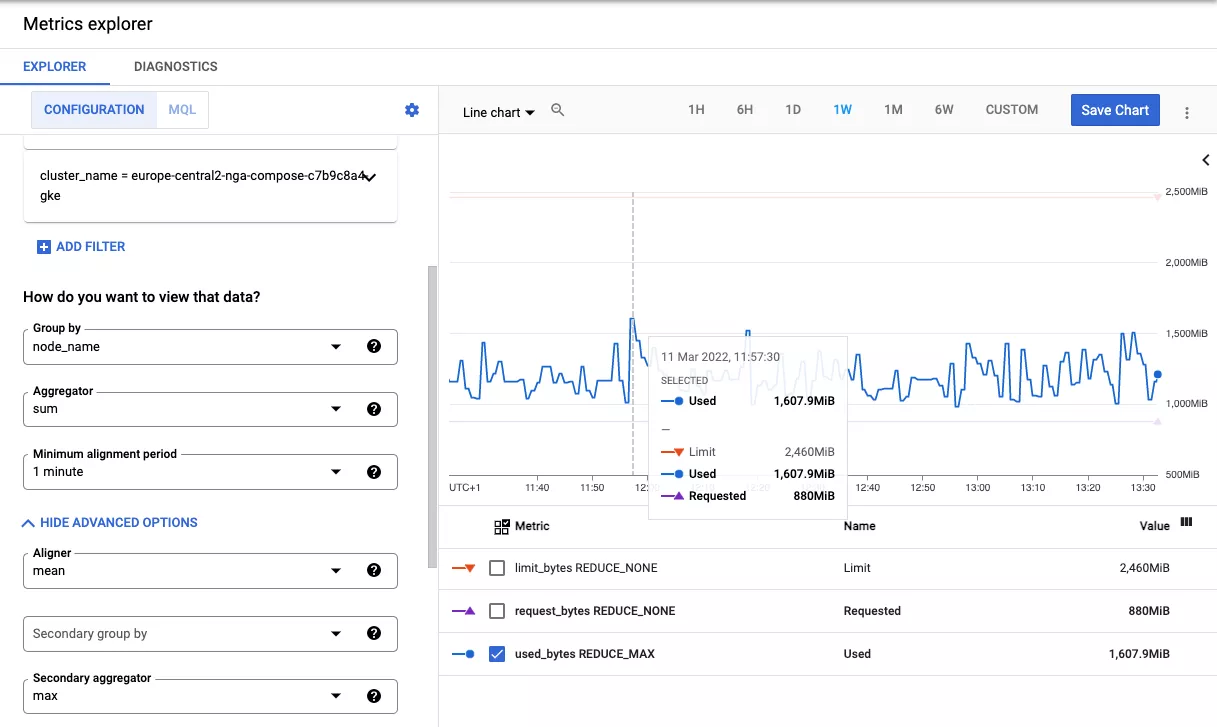
The overhead: 1.6GiB of RAM for built-in Cloud Composer processes on every worker.
Maximum number of tasks
Now we’re ready to estimate available memory and the maximum number of concurrent tasks. I would also recommend making some reservations if you want a stable environment without unexpected incidents during your on-duty shift. For 20% reservation, the Cloud Composer cluster capacity will be defined as follows:
| Worker | Formula | Available Cluster Memory |
|---|---|---|
| n1-standard-1 | 3 * (2.56GiB - 1.6GiB) - 20% | 2.47GiB |
| n2-standard-2 | 3 * (5.9GiB - 1.6GiB) - 20% | 11.08GiB |
| n2-highmem-2 | 3 * (~13.4GiB - 1.6GiB) - 20% | 30.41GiB |
How many concurrent tasks can be run on our Cloud Composer cluster? Not so many, at least not on the cluster of the cheapest virtual machines.
| Worker | Formula | Maximum Tasks |
|---|---|---|
| n1-standard-1 | 2.47GiB / 220MiB | 11 |
| n2-standard-2 | 11.08GiB / 220MiB | 51 |
| n2-highmem-2 | 30.41GiB/ 220MiB | 141 |
Apache Airflow tuning
Parallelism and worker concurrency
When the maximum number of tasks is known, it must be applied manually in the Apache Airflow configuration. If not, Cloud Composer sets the defaults and the workers will be under-utilized or airflow-worker pods will be evicted due to memory overuse.
- core.parallelism – The maximum number of task instances that can run concurrently in Airflow regardless of worker count. Set to 18 for 3-nodes Cloud Composer cluster if not specified explicitly.
- celery.worker_concurrency – Defines the number of task instances that a worker will take. Set to 6 by Cloud Composer if not specified explicitly.
In my 3-workers cluster scenario the following settings should be applied.
| Worker | core.parallelism | celery.worker_concurrency |
|---|---|---|
| n1-standard-1 | 12 | 4 |
| n2-standard-2 | 51 | 17 |
| n2-highmem-2 | 141 | 47 |
As you can see, Cloud Composer defaults don’t match any of the presented worker types. Defaults for the cluster of the smallest virtual machines are too optimistic, and I observed many pod evictions. For the virtual machines with 4GiB of RAM or more, the cluster with default settings is underutilized, you pay for nothing.
Scheduler
I have also found two other Apache Airflow properties worth modifying:
- scheduler.min_file_process_interval – The minimum interval after which a DAG file is parsed and tasks are scheduled, 0 if not specified.
- scheduler.parsing_processes – Defines how many DAGs parsing processes will run in parallel, 2 if not specified.
I highly recommend setting scheduler.min_file_process_interval to at least 30 seconds, to avoid high CPU usage on the worker where the airflow-scheduler pod is running.
The scheduler is running only on the single worker,
so it heavily impacts the other processes and tasks on this worker.
The scheduler.parsing_processes should be set to max(1, number of CPUs - 1), set to 1 unless you define workers with 3 CPUs or more.
Again it should lower the CPU utilization on the worker which is running the airflow-scheduler pod.
Scheduler is an important process of Apache Airflow. When it doesn’t work properly you will observe many weird and hard to debug flaws.
Monitoring
Cloud Composer has been already configured in the optimal way, but the batch job scheduling might be a dynamic environment. DAGs come and go, from time to time the history needs to be re-calculated which causes high pressure on the tasks scheduling as well. Fortunately Cloud Composer provides many performance related metrics to monitor.
composer.googleapis.com/environment/worker/pod_eviction_count – The number of worker pods evictions.
If the evictions are observed, all task instances running on that pod are interrupted, and later marked as failed.
The pod’s eviction is a clear indicator that too many heavy tasks were running on the worker.
You can either: lower core.parallelism and celery.worker_concurrency or scale up the cluster.
composer.googleapis.com/environment/unfinished_task_instances – The number of running task instances.
If the metric is close to the core.parallelism you should plan to scale up the cluster.
I would prefer vertical scaling than horizontal, Kubernetes and Cloud Composer overhead is lower for larger virtual machines.
Based on the CPU and memory metrics you should decide about the target virtual machine family (normal or highmem).
composer.googleapis.com/environment/dag_processing/total_parse_time – The number of seconds taken to scan and import all DAG files. The processing time should be 30 seconds or less, if not the tasks scheduling seems to be very unreliable. If the parsing time is too high:
- Optimize DAGs, see the official recommendation for the top level Python code
- Increase
scheduler.min_file_process_interval, but longer interval also causes higher latency for the task scheduling. - Use workers with 3 CPUs or more, and increase
scheduler.parsing_processesaccordingly to allow parallel DAGs parsing.
kubernetes.io/container/cpu/core_usage_time – CPU usage on the workers. Pay special attention to the worker with the airflow-scheduler pod. High CPU usage on that worker would have had a negative impact on the regular tasks.
kubernetes.io/container/memory/used_bytes – Memory usage on the workers.
If the metric is close to Kubernetes allocatable memory for the worker,
you can either: lower core.parallelism and celery.worker_concurrency or scale up the workers.
Summary
Cloud Composer is a managed service of Apache Airflow hosted on Google Cloud Platform. However, “managed” doesn’t relieve you from the proper configuration to squeeze more processing power for less money. In the end, Cloud Composer isn’t the cheapest and Apache Airflow isn’t the most lightweight service on this planet.
You should also remember that Cloud Composer 1.x and Apache Airflow 1.x aren’t actively developed anymore. I’m really keen to repeat the same tuning exercise for Cloud Composer 2.x and check how far better it’s from the predecessor. The official documentation Optimize environment performance and costs looks promising.
Last but not least, I would like to thank Piotrek and Patryk for the fruitful discussions.
Comments