
Dataproc is a fully managed and highly scalable Google Cloud Platform service for running Apache Spark. However, “managed” doesn’t relieve you from the proper configuration to squeeze more processing power for less money. Today you will learn the easiest method to configure Dataproc and Spark together to get optimal performance and lower cost.
The article is for Dataproc 1.5 and Spark 2.x only. It might also work for Dataproc 2.x and Spark 3.x, but I have not verified the latest versions.
Clear spark.properties
The setup heavily depends on the defaults applied by Dataproc, spark.properties must not interfere with them. Ensure that you DO NOT DEFINE any of the following parameters:
- spark.executor.instances
- spark.[driver|executor].memory
- spark.[driver|executor].memoryOverhead
- spark.executor.cores
Totally counterintuitive, isn’t it? Especially if you have been deploying many non-trivial Spark jobs on-premise. When I was migrating my Spark jobs to the Google Cloud I fell into the same trap, I was trying to lift and shift the Spark job configuration unchanged. But I quickly turned out that I was completely wrong.
Spark Dynamic Allocation magic
Instead of tuning the Spark jobs manually, enable Spark dynamic allocation. The dynamic allocation is enabled on the Dataproc clusters by default, but the property is so important that I want to set it explicitly.
1
spark.dynamicAllocation.enabled: true
Now the Spark jobs start on a single executor and scale up to fill all the available ephemeral Dataproc cluster resources. Below you can see the YARN allocations for the cluster of 16 “n2-highmem-4” virtual machines.
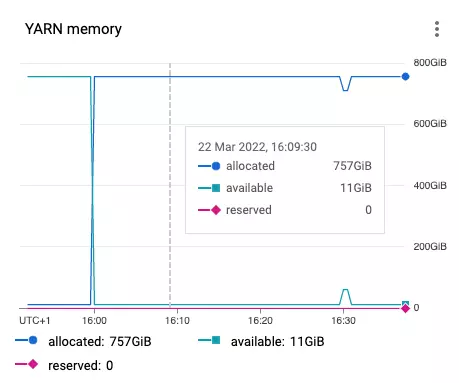
The Spark job scales up to the maximum in ~ 8-9 minutes, but it heavily depends on the job logic. My jobs read data from BigQuery using Spark BigData Connector. During the first minutes BigQuery jobs store query results into materialization dataset. Nothing to do for the Spark job itself, so the job doesn’t scale up at the very beginning.
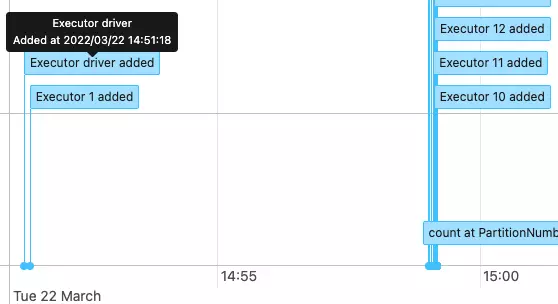
What about Spark executor instances? By default, Dataproc configures two YARN containers on every virtual machine. So, the cluster of 16 virtual machines has 32 available YARN containers:
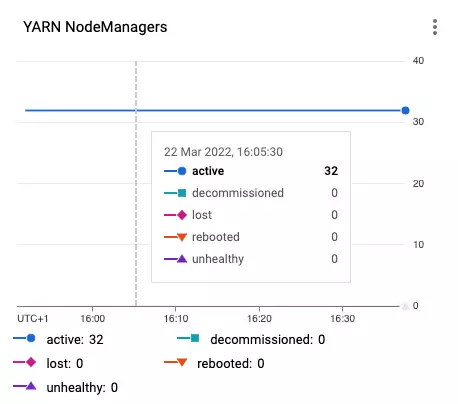
Based on the number of containers Spark dynamically allocates up to 32 executors. The properties “spark.executor.cores” and “spark.executor.memory” are set accordingly to the half of the virtual machine resources. Extremely convenient!
For the “n2-highmem-4” workers the following defaults are applied:
1
2
spark.executor.cores: 2
spark.executor.memory: 11171m
Please pay attention to the fact that the allocated memory already takes into account Dataproc YARN and Spark overheads.
Automatic memory tuning
If you observe behavior of Spark executors being killed by YARN due to memory over-allocation, DO NOT CHANGE “spark.executor.memoryOverhead” as usual. It would break the whole Dataproc defaults magic.
When your cluster is defined within “n2-standard-4” machines, the following settings are applied for each Spark executor:
1
2
spark.executor.memory: 5586m
spark.executor.memoryOverhead: 5586m * 0.1 = 558.6m.
From my experiences, 558MiB memory overhead isn’t enough for the Spark job running on two cores. The documentation recommends using highmem virtual machines if Spark workers are killed by YARN due to memory errors.
- It doesn’t break the automagical memory calculation
- The memory overhead for “n2-highmem-4” is
11171m * 0.1 = 1117m - The memory overhead depends on the Spark parallelism, so when the “spark.executor.cores” stays unchanged it should solve the memory over-allocation issue
Dataproc Enhanced Flexibility Mode
Dataproc EFM is crucial if you are using preemptible virtual machines. Without EFM the job execution could be very unpredictable (think about black week when the resources might not be easily available even in GCP). There are two important rules to apply:
- If your Spark job requires more than 2 virtual machines you could delegate ~ 75% of workload to the secondary, preemptible machines. Look for “Spot VM” pricing, the spot instances are 3x-10x cheaper than regular ones - it’s a huge saving.
- Use local SSD disks for the primary workers. Primary workers are responsible for data shuffling, so the best available IO is a must. According to the documentation one local disk should be assigned for every 4 CPUs.
To configure EFM mode use the following Dataproc cluster properties:
1
2
dataproc:efm.spark.shuffle: primary-worker
hdfs:dfs.replication: 1
I’ve found one important lower-bound constraint for the number of primary Dataproc workers.
The local HDFS is located on the primary workers only, and all Spark shuffle results must fit into this space.
Each local SSD disk has 375GiB but YARN allocates only up to 90% of total capacity.
For 8 primary workers with the single local SSD disk the total HDFS capacity is 8 * 375GiB * 0.9 = 2.7TiB - exactly as shown below:
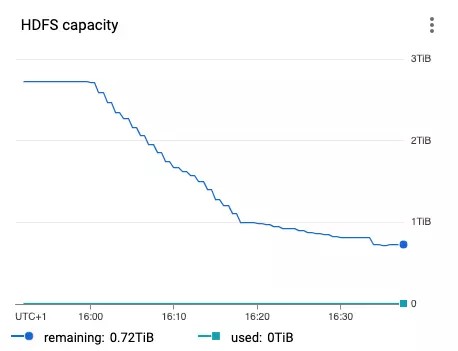
You have to allocate as many primary workers as needed to keep all Spark job shuffle data. I would not recommend assigning more than one local ssd to the primary node to increase the capacity. Just increase the number of primary workers.
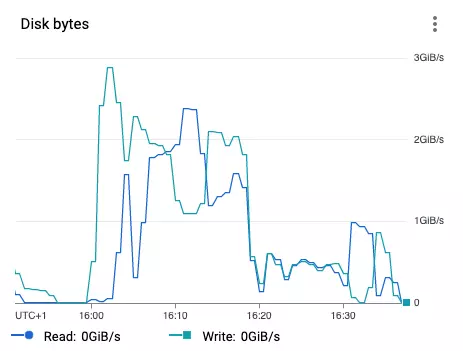
The local SSD disks have impressive performance, and the metrics shows that disks’ IO is only partially utilized.
A single SSD connected with SCSI should handle 390 MB/sec (read) and 270 MB/sec (write).
It gives a total 8 * 390MB = 3.12GB = 2.9GiB (read) and 8 * 270MB = 2.16GB = 2.01 GiB (write).
You could also attach local disks using NVMe to get better performance, 660 MB/sec (read) and 350 MB/sec (write).
See the official documentation for more details.
I would thank Michał Misiewicz for reporting a bug in my initial calculations ❤️
CPU utilization
Finally, the CPU utilization should be verified. The north star is to utilize 100% of available CPU for the whole job running duration. As you can see below it isn’t always possible :)
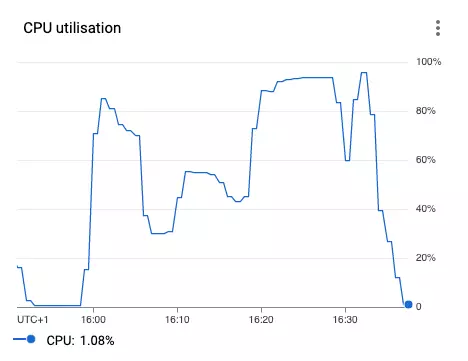
If you observe low CPU utilization, follow the checklist:
- Verify that “spark.sql.shuffle.partitions” is set to at least
number of vCPU * 3(200 if not defined) - Use highmem workers, the job may be memory/io bound, not CPU bound
- Increase the ratio between primary and secondary workers, low CPU usage might be caused by heavy shuffling, more primary workers give more parallelism
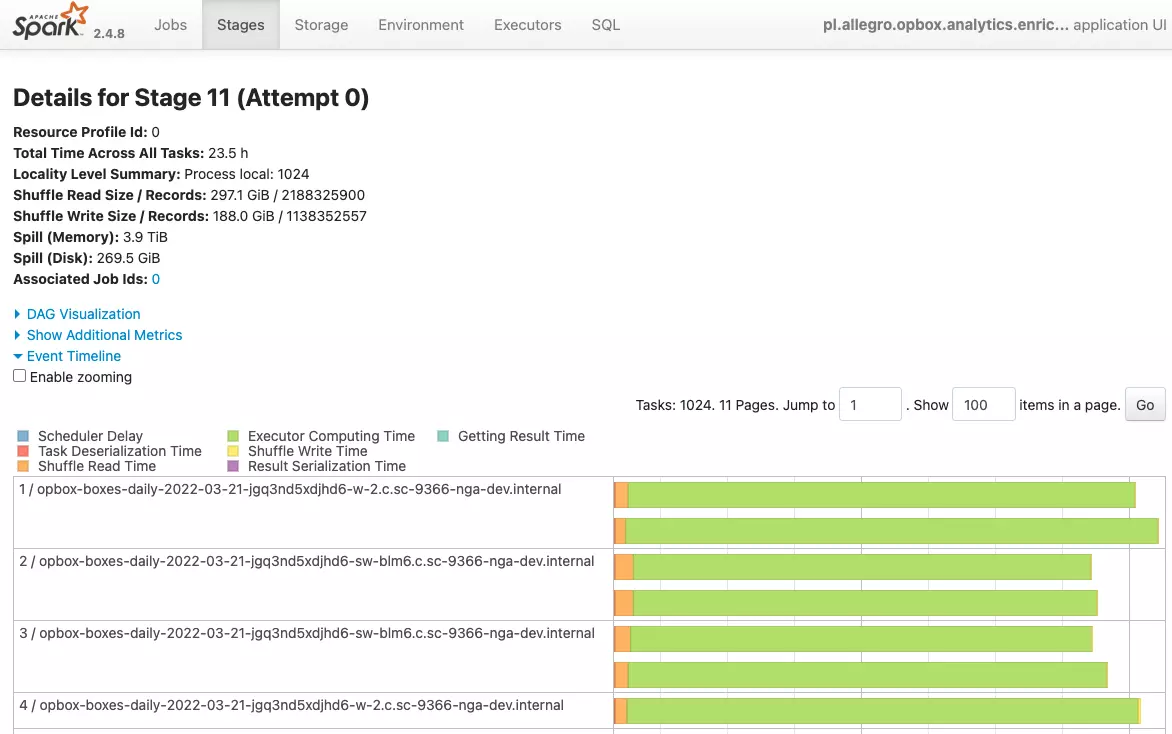
If the lower CPU usage is caused by shuffling, check the Spark metrics again. ”Shuffle Read Time” metric should be only a small portion of the total time as presented below.
Summary
With dynamic allocation enabled, Dataproc and Apache Spark combo finally looks like a fully managed solution. Just set the Dataproc cluster size, virtual machine family, define primary to secondary workers ratio and voilà - the Spark jobs align automagically to the available resources.
Comments