
Last week I virtually attended Apache Beam Summit 2022 held in Austin, Texas. The event concentrates around Apache Beam and the runners like Dataflow, Flink, Spark or Samza. Below you can find my overall impression of the conference and notes from several interesting sessions. If some aspect was particularly appealing I put the reference to supplementary materials.
Overview
The conference was a hybrid event, all sessions (except for workshops) were live-streamed for an online audience for free.
During the sessions you could ask the questions on the streaming platform, and the questions from the online audience were answered by the speakers. When the sessions had finished, they were available on the streaming platform. I was able to replay afternoon sessions the next day in the morning, very convenient for people in non US timezones like me.
For the two days the program was organized within three tracks, the third day was dedicated to the onsite workshops but there was also one track for the online audience.
Highly recommended sessions
Google’s investment on Beam, and internal use of Beam at Google
The keynote session was presented by Kerry Donny-Clark (manager of the Apache Beam team at Google).
- Google centric keynotes, I missed some comparison between Apache Beam / Dataflow and other data processing industry leaders
- A few words about new runners: Hazelcast, Ray, Dask
- TypeScript SDK as an effect of internal Google hackathon
- Google engagement in Apache Beam community
How the sausage gets made: Dataflow under the covers
The session was presented by Pablo Estrada (software engineer at Google, PMC member).
- Excellent session, highly recommended if you deploy non-trivial Apache Beam pipelines on Dataflow runner
- What does “exactly once” really mean in Apache Beam / Dataflow runner

- Runner optimizations: fusion, flatten sinking, combiner lifting
- Interesting papers, they help to understand Dataflow runner principles: Photon, MillWheel
- Batch vs streaming: same controller, but data path is different. Different engineering teams, no plans to unify.
- Batch bundle: 100–1000 elements vs. streaming bundle: < 10 elements (when pipeline is up-to-date)
- Controlling batches: GroupIntoBatches
- In streaming EACH element has a key (implicit or explicit)

- Processing is serial for each key!

Introduction to performance testing in Apache Beam
The session was presented by Alexey Romanenko (principal software engineer at Talend, PMC member).
There are 4 performance tests categories in Apache Beam and the tests results are available at https://metrics.beam.apache.org
- IO integration tests
- only for batch
- only for Java SDK
- not for all IOs
- only read/write time metrics
- Core Beam tests
- synthetic sources
- ParDo, ParDo with SideInput, GBK, CoGBK
- batch and streaming
- all SDKs
- Dataflow, Flink, Spark
- many metrics
- Nexmark
- batch and streaming
- Java SDK
- Dataflow, Flink, Spark
- small scale, not industry standard (hard to compare)
- TPC-DS
- industry standard;
- SQL based
- batch only
- CSV and Parquet as input
- Dataflow, Spark, Flink
- 25 of 103 queries currently passes
How to benchmark your Beam pipelines for cost optimization and capacity planning
The session was presented by Roy Arsan (solution architect at Google).
- How to verify performance and costs for different Dataflow setups using predefined scenarios?
- Use PerfKit benchmark!
- Runtime, CPU utilization and costs for different workers
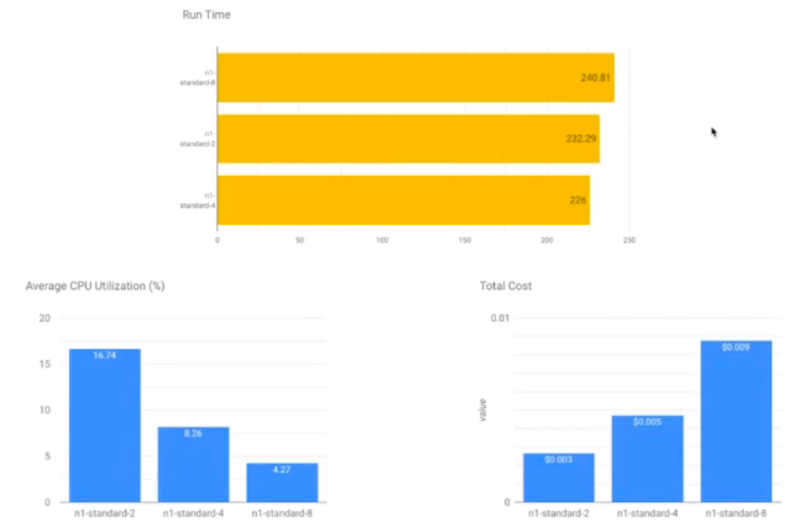
- Results for the streaming job scenario
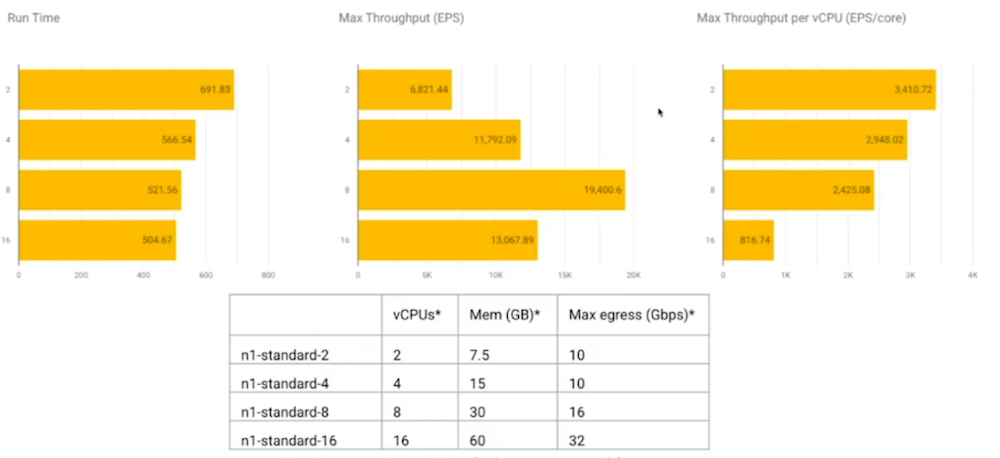
Palo Alto Networks’ massive-scale deployment of Beam
The session was presented by Talat Uyarer (Senior Principal Software Engineer at Palo Alto Networks).
- 10k streaming jobs!
- Custom solution for creating / deploying / managing Dataflow jobs
- Custom solution for managing Kafka clusters
- Example job definition
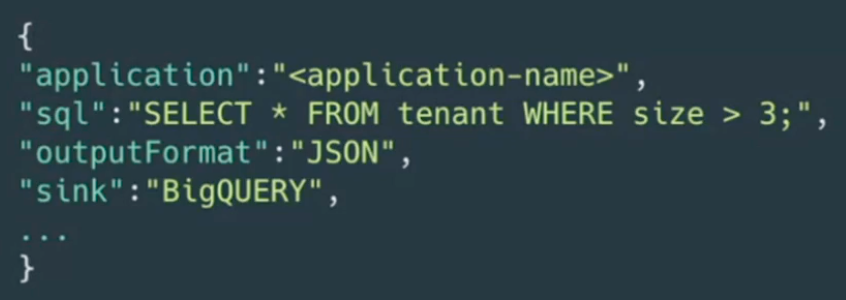
- Custom sinks (unfortunately no details)
- Rolling updates or fallback to drain/start (but with the job cold start to minimize downtime)
- Many challenges with Avro schema evolution, see case study
New Avro Serialization And Deserialization In Beam SQL
The session was presented by Talat Uyarer (Senior Principal Software Engineer at Palo Alto Networks).
- How can we improve latency while using BeamSQL and Avro payloads?
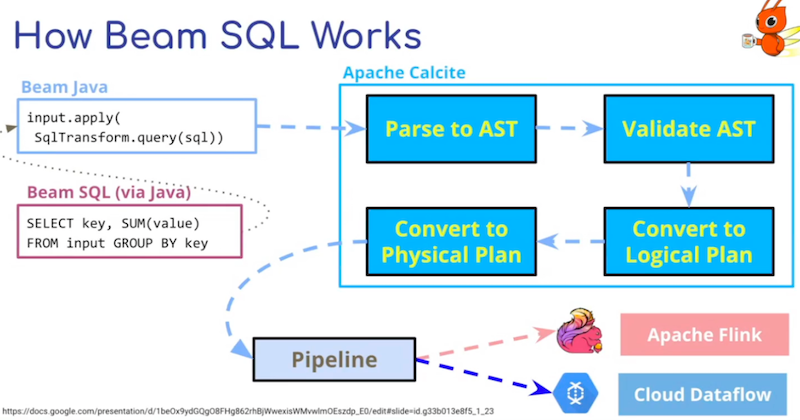
- Critical elements: Table Provider + Data to Beam Row converters
- New Avro converter inspired by RTB House Fast Avro
- The future

RunInference: Machine Learning Inferences in Beam
The session was presented by Andy Ye (software engineer at Google).
- Reusable transform to run ML inferences, see documentation
- Support for PyTorch, SciKit and TensorFlow
- More in the future

Unified Streaming And Batch Pipelines At LinkedIn Using Beam
The session was presented by Shangjin Zhang (staff software engineer at LinkedIn) and Yuhong Cheng (software engineer at Linkedin).
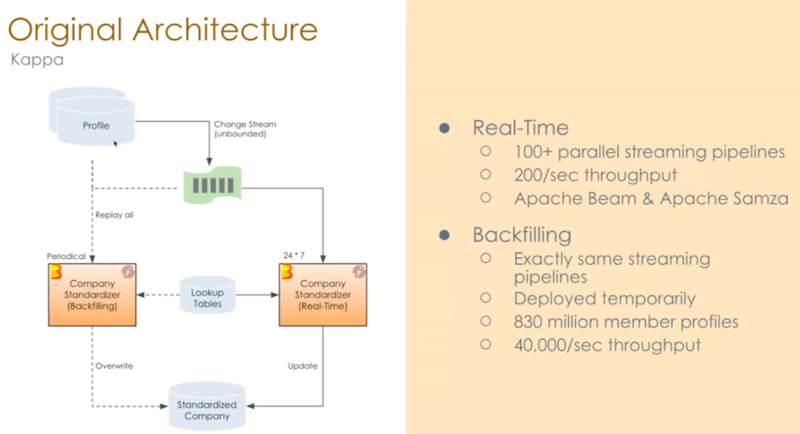
- Streaming back-filling issues : hard to scale, flood on lookup tables, noisy neighbor to regular streaming pipelines
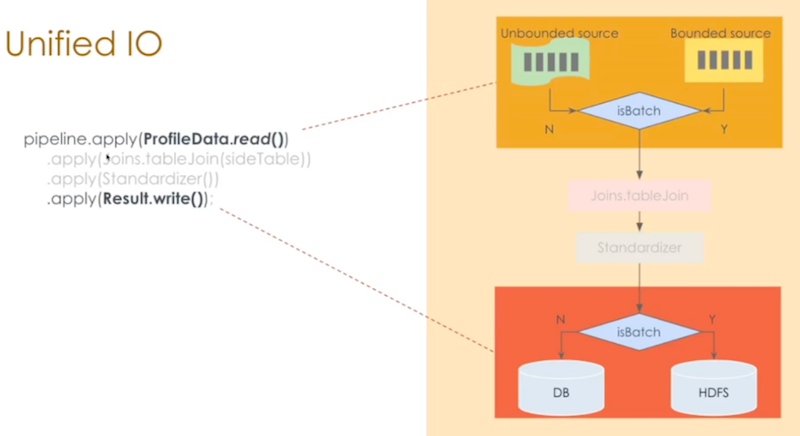
- Single codebase: Samza runner for streaming, Spark runner for batch
- Unified PTransform with expandStreaming and expandBatch methods
- Unified table join: key lookup for streaming and coGroupByKey for batch
- No windows in the pipeline (lucky them)
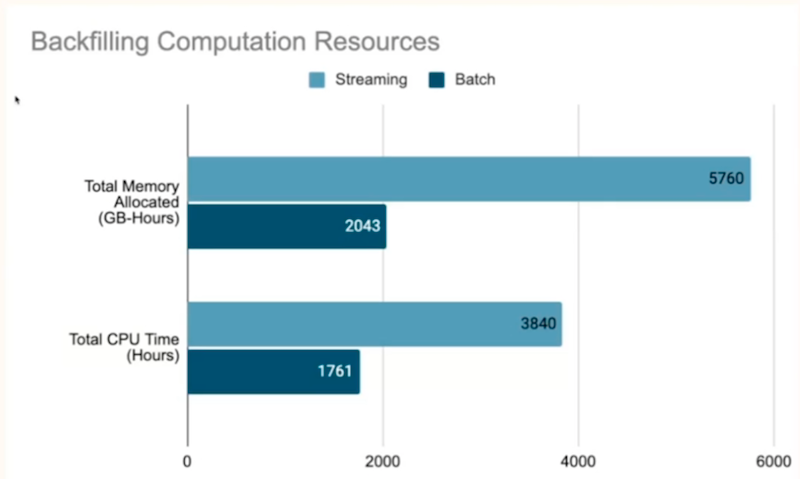
- Job duration decreased from 450 minutes (streaming) to 25 minutes (batch)
Log ingestion and data replication at Twitter
The session was presented by Praveen Killamsetti and Zhenzhao Wang (staff engineers at Twitter) .
Batch ingestion architecture - Data Lifecycle Manager:
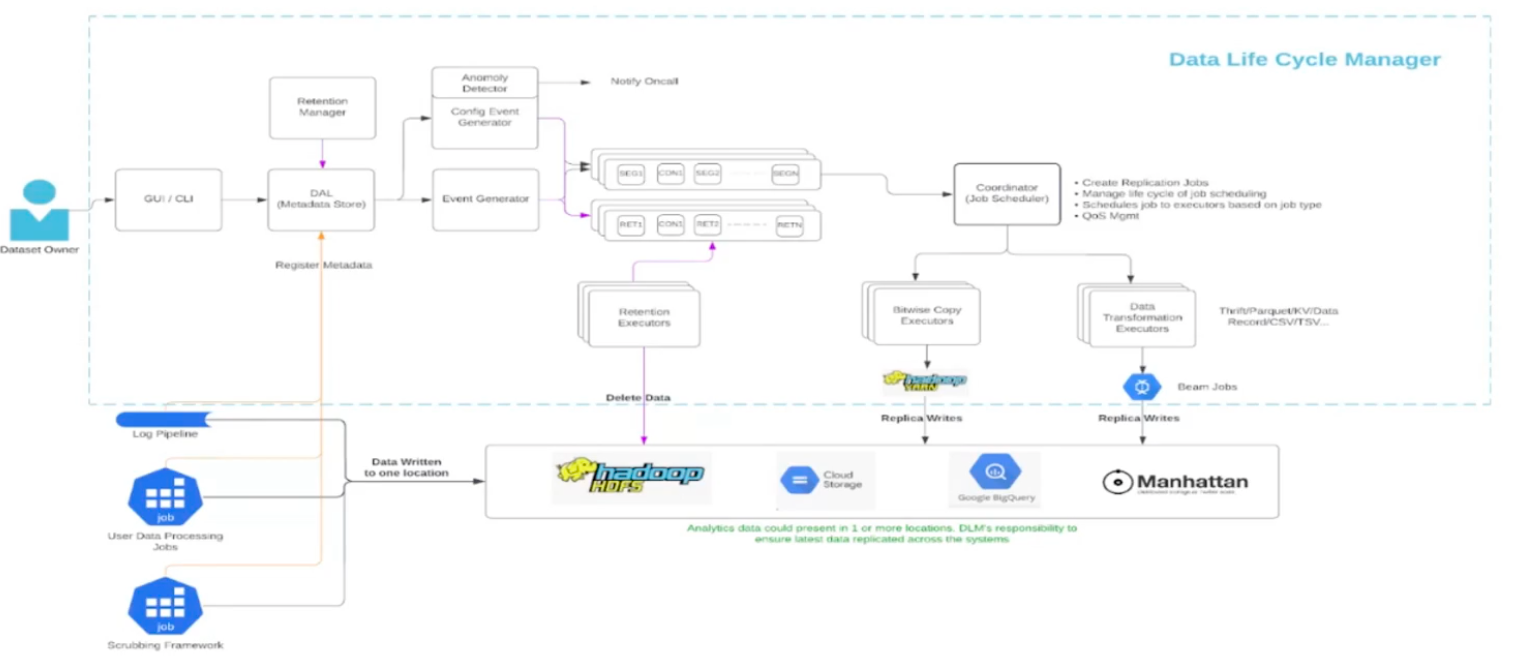
- Many data sources: HDFS, GCS, S3, BigQuery, Manhattan
- Versioned datasets with metadata layer
- Replicates data to all data sources (seems to be very expensive)
- GUI for configuration, DLM manages all the jobs
- Plans: migrate 600+ custom data pipelines to DLM platform
Streaming log ingestion - Sparrow

- E2E latency - up to 13 minutes instead of hours
- One Beam Job and Pubsub Subscription per dataset per transformation (again seems to be very expensive)
- Decreased job resource usage by 80–86% via removing shuffle in BigQuery IO connector
- Reduced worker usage by 20% via data (batches) compression on Pubsub
- Optimized schema conversion logic (Thrift -> Avro -> TableRow)
Detecting Change-Points in Real-Time with Apache Beam
The session was presented by Devon Peticolas (principal engineer at Oden Technologies).
- Nice session with realistic, non-trivial streaming IOT scenarios
- How Oden uses Beam: detecting categorical changes based on continues metrics

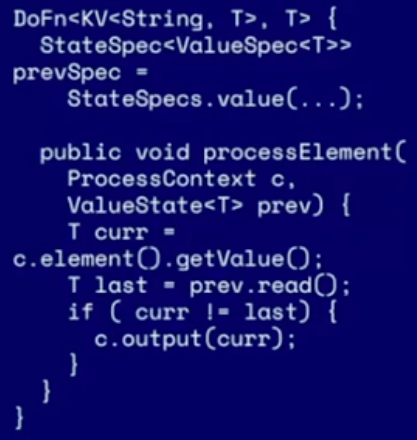
- Attempt 1: stateful DoFn - problem: out of order events (naive current and last elements’ comparison)
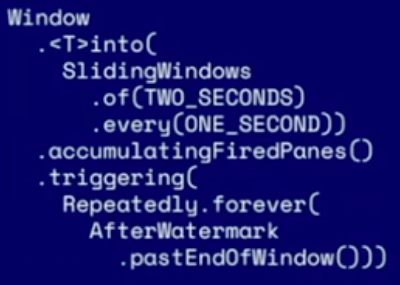
- Attempt 2: watermark triggered window - problem: lag for non-homogeneous data sources
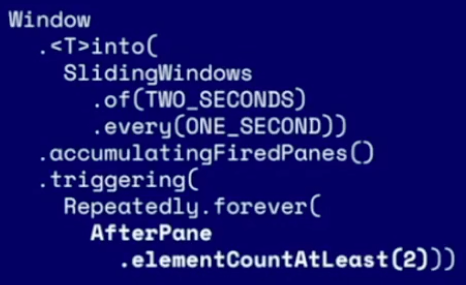
- Attempt 3: data triggered window - problem: sparse data when not all events are delivered
- Smoothing, see the original session it’s hard to summarize concept in the single sentence
Worth seeing sessions
Tailoring pipelines at Spotify
The session was presented by Rickard Zwahlen (data engineer at Spotify).
- Thousands of relatively similar data pipelines to manage
- Reusable Apache Beam jobs packed as Docker images and managed by Backstage
- Typical use cases: data profiling, anomaly detection
- More complex use cases - custom pipeline development
Houston, we’ve got a problem: 6 principles for pipelines design taken from the Apollo missions
The session was presented by Israel Herraiz and Paul Balm (strategic cloud engineers at Google).
- Nothing spectacular but worth seeing, below you can find the agenda

Strategies for caching data in Dataflow using Beam SDK
The session was presented by Zeeshan (cloud engineer).
- Side input (for streaming engine stored in BigTable)
- Util
apache_beam.utils.shared.Shared(python only) - Stateful DoFn (per key and window), define elements TTL for the global window
- External cache
Migration Spark to Apache Beam/Dataflow and hexagonal architecture + DDD
The session was presented by Mazlum Tosun.
- DDD/Hexagonal architecture pipeline code organization
- Static dependency injection with Dagger
- Test data defined as JSON files
I would say: overkill … I’m going to write the blog post on how to achieve testable Apache Beam pipelines aligned to DDD architecture in a simpler way :)
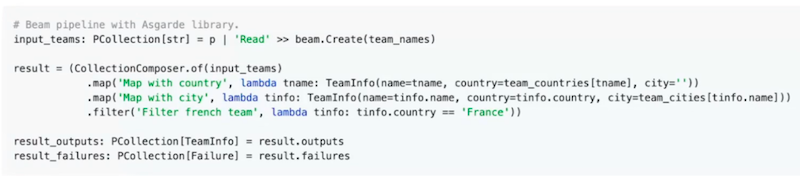
Error handling with Apache Beam and Asgarde library
The session was presented by Mazlum Tosun.
- Functional way to handle and combine Failures, Beam native method is too verbose (try/catch, exceptionsInto, exceptionsVia)
- See https://github.com/project-asgard/asgard
Asgard error handling for Java:

Asgard error handling for Python:
Beam as a High-Performance Compute Grid
The session was presented by Peter Coyle (Head of Risk Technology Engineering Excellence at HSBC) and Raj Subramani.
- Risk management system for investment banking at HSBC
- Flink runner & Dataflow runner
- Trillion evaluations (whatever it means)
- Choose the most efficient worker type for cost efficiency
- Manage shuffle slots quotas for batch Dataflow
- Instead of reservation (not available for Dataflow) define disaster recovery scenario and fallback to more common worker type

Optimizing a Dataflow pipeline for cost efficiency: Lessons learned at Orange
The session was presented by Jérémie Gomez (cloud consultant at Google) and Thomas Sauvagnat (data engineer at Orange).
- How to store Orange LiveBox data into BigQuery (33TB of billed bytes daily)?
- Initial architecture: data on GCS, on-finalize trigger, Dataflow streaming job notified from Pubsub, read files from GCS and store to BQ
- It isn’t cheap stuff ;)
- The optimization plan
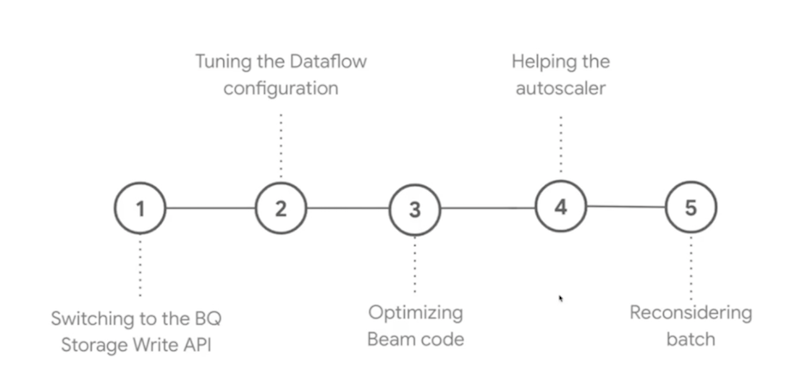
- Storage Write API instead on Streaming Inserts
- BigQuery batch loads didn’t work as well
- N2 workers instead of N1
- Smaller workers (n2-standard-8 instead of n2-standard-16)
- Disabled autoscaling (the pipeline latency isn’t so important, Dataflow autoscaler policy can not be configured)
- USE BATCH INSTEAD OF STREAMING if feasible
Relational Beam: Process columns, not rows!
The session was presented by Andrew Pilloud and Brian Hulette (software engineers at Google, Apache Beam committers)
- Beam isn’t relational, is row oriented, data is represented as bytes
- What’s needed: data schema, metadata of computation

- Batched DoFn (doesn’t exist yet) https://s.apache.org/batched-dofns
- Projection pushdown (currently for BigQueryIO.TypedRead only; 2.38 batch, 2.41 streaming)
- Don’t use
@ProcessContext- it deserializes everything, use@FieldAccessinstead - Use relational transforms:
beam.Select,beam.GroupBy
Scaling up pandas with the Beam DataFrame API
The session was presented by Brian Hulette (software engineer at Google, Apache Beam committer).
- Nice introduction to Pandas
- DataframeTransform and DeferredDataFrame
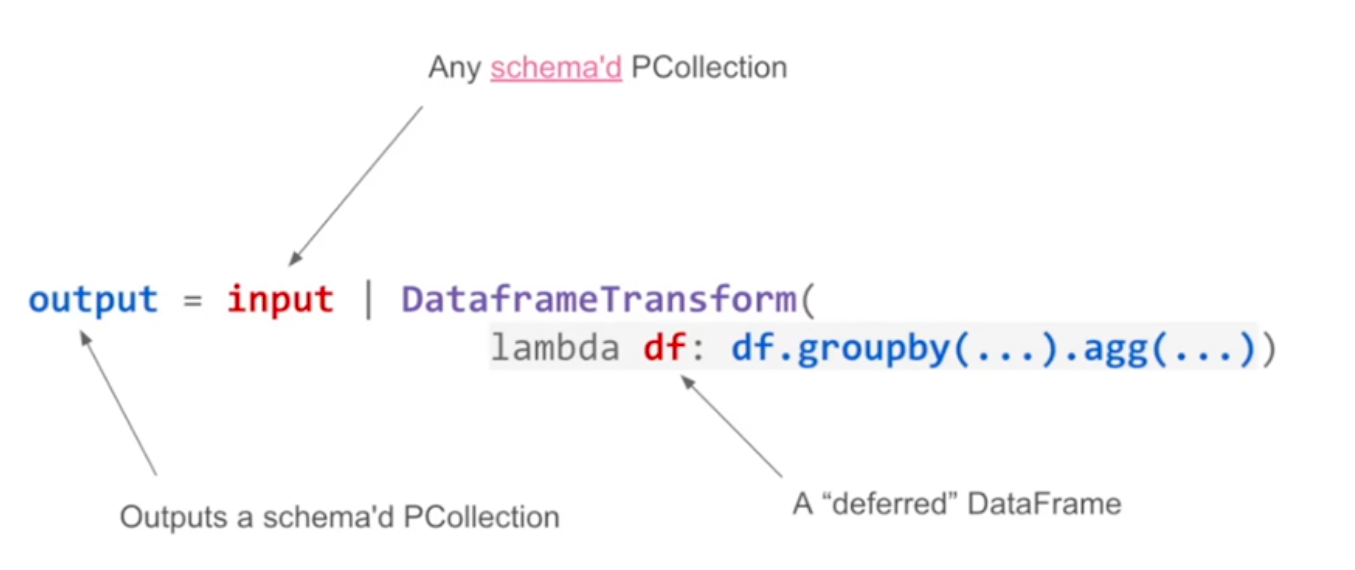
- Dataframe code → Expression tree → Beam pipeline
- Compliance with Pandas is limited as for now
- 14% of Pandas operations are order-sensitive (hard to distribute)
- Pandas windowing operations transformed into Beam windowing would be a real differentiator in the future
Improving Beam-Dataflow Pipelines For Text Data Processing
The session by Sayak Paul and Nilabhra Roy Chowdhury (ML engineers at Carted)
- Use variable sequence lengths for sentence encoder model
- Sort data before batching
- Separate tokenization and encoding steps to achieve full parallelism
- More details in the blog post

Summary
I would thank organizers and speakers for the Beam Summit conference. The project needs such events to share the knowledge of how leading organizations use Apache Beam, how to apply advanced data processing techniques and how the runners execute the pipelines.
Below you could find a few takeaways from the sessions:
- Companies like Spotify, Palo Alto Networks or Twitter develop custom, fully managed, declarative layers on top of Apache Beam. To run thousands of data pipelines without coding and excessive operations.
- Streaming pipelines are sexy but much more expensive (and complex) than batch pipelines.
- Use existing tools like PerfKit for performance/cost evaluation. Check Apache Beam performance metrics to compare different runners (for example if you want to migrate from JDK 1.8 to JDK 11).
- Understand the framework and the runner internals, unfortunately it’s necessary for troubleshooting. Be aware that Dataflow batch and streaming engines are developed by different engineering teams.
- Cloud resources aren’t infinite, be prepared and define disaster recovery scenarios (fallback to more common machine types).
- Future is bright: Beam SQL, integration with ML frameworks, column oriented vectorized execution, new runners
Comments