
This week, I attended Flink Forward in Berlin, Germany. The event celebrated the 10th anniversary of Apache Flink. Below, you can find my overall impressions of the conference and notes from several interesting sessions. If an aspect was particularly appealing, I included a reference to supplementary materials.

I don’t use Flink on a daily basis, but I hoped to gain some inspiration that I could apply to my real-time data pipelines running on GCP Dataflow.
Keynotes
- Flink 2.0 announced during the first day of the conference, perfect timing
- Stephan Ewen with Feng Wang presented 15 years of the project history Apache Flink, which emerged around 2014, originally started as the Stratosphere project at German universities in 2009

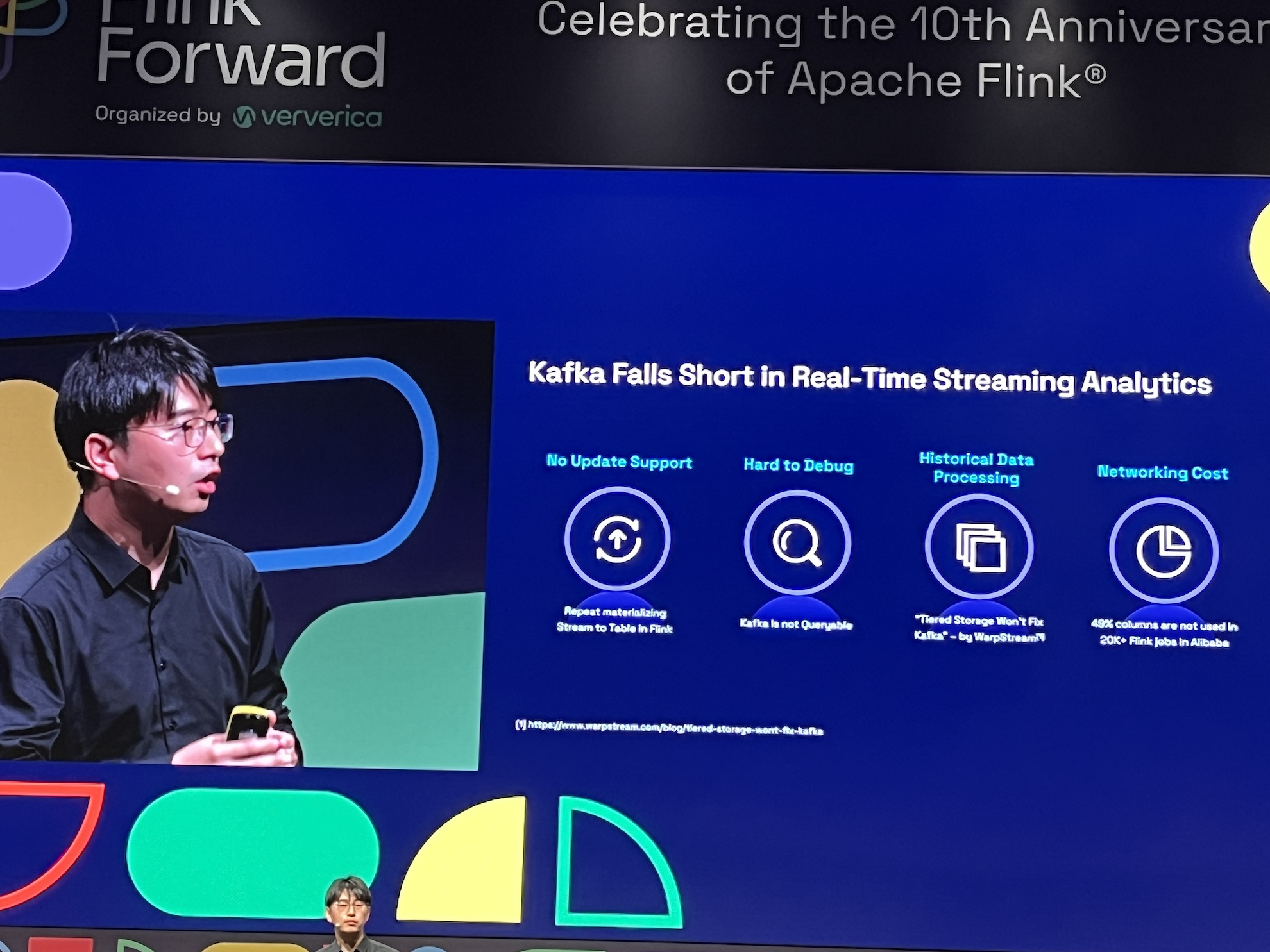
- Kafka fails short in real-time streaming analytics
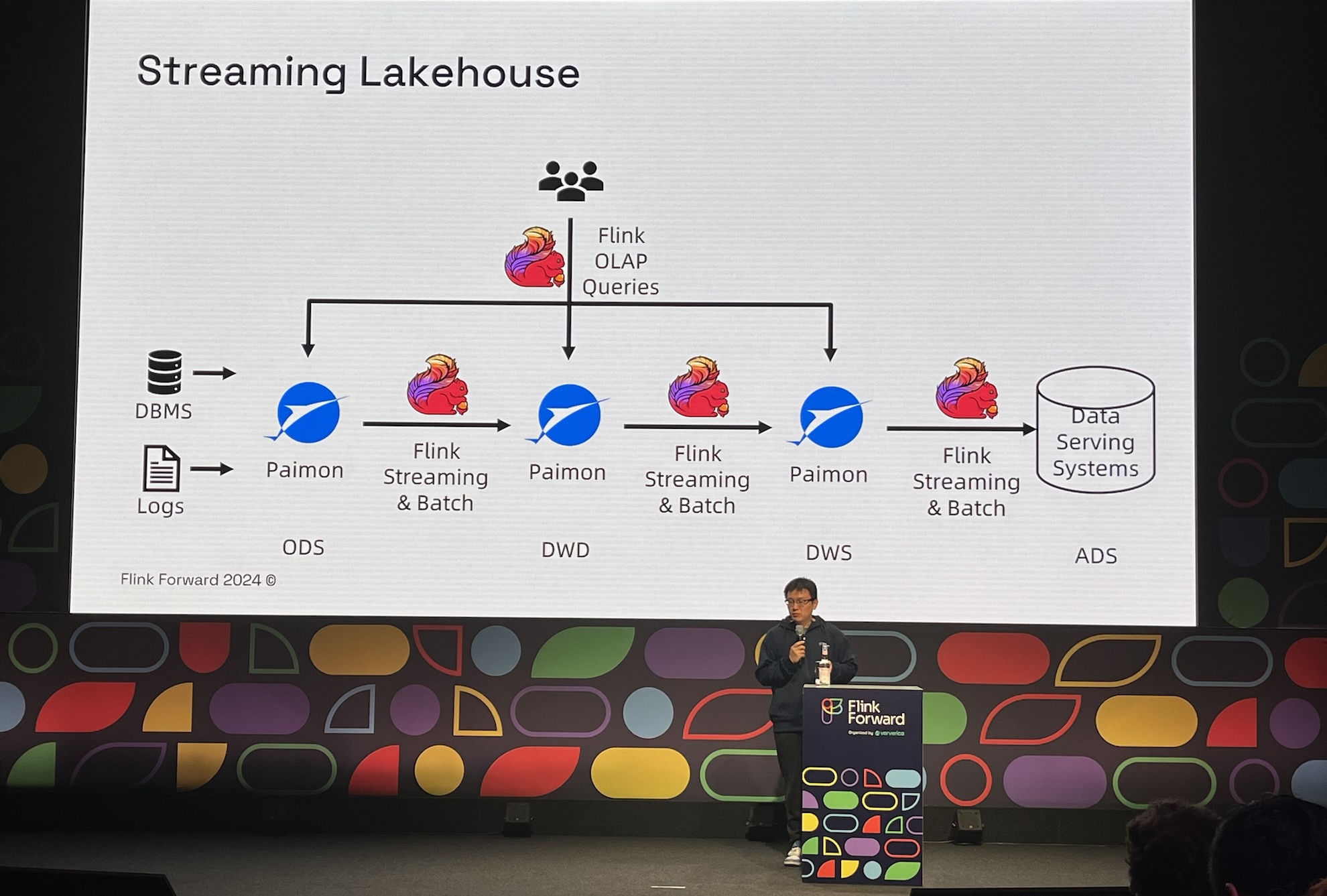
- Truly unified batch and streaming with Apache Paimon: Streaming Lakehouse.
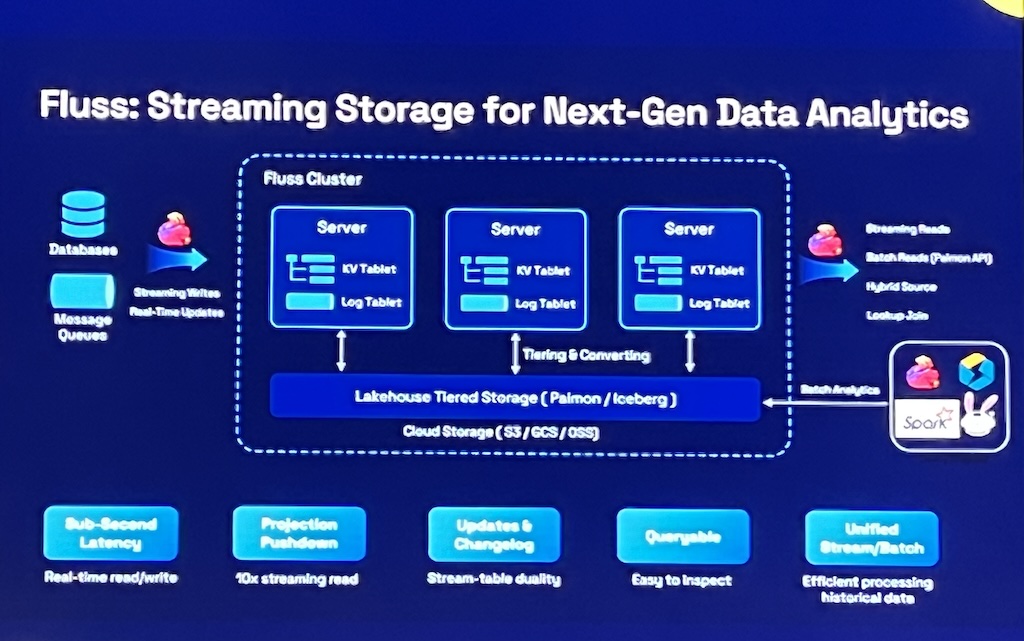
- Fluss: Streaming storage for next-gen data analytics, it’s going to be open-sourced soon. Apologies for the low quality picture.
Revealing the secrets of Apache Flink 2.0
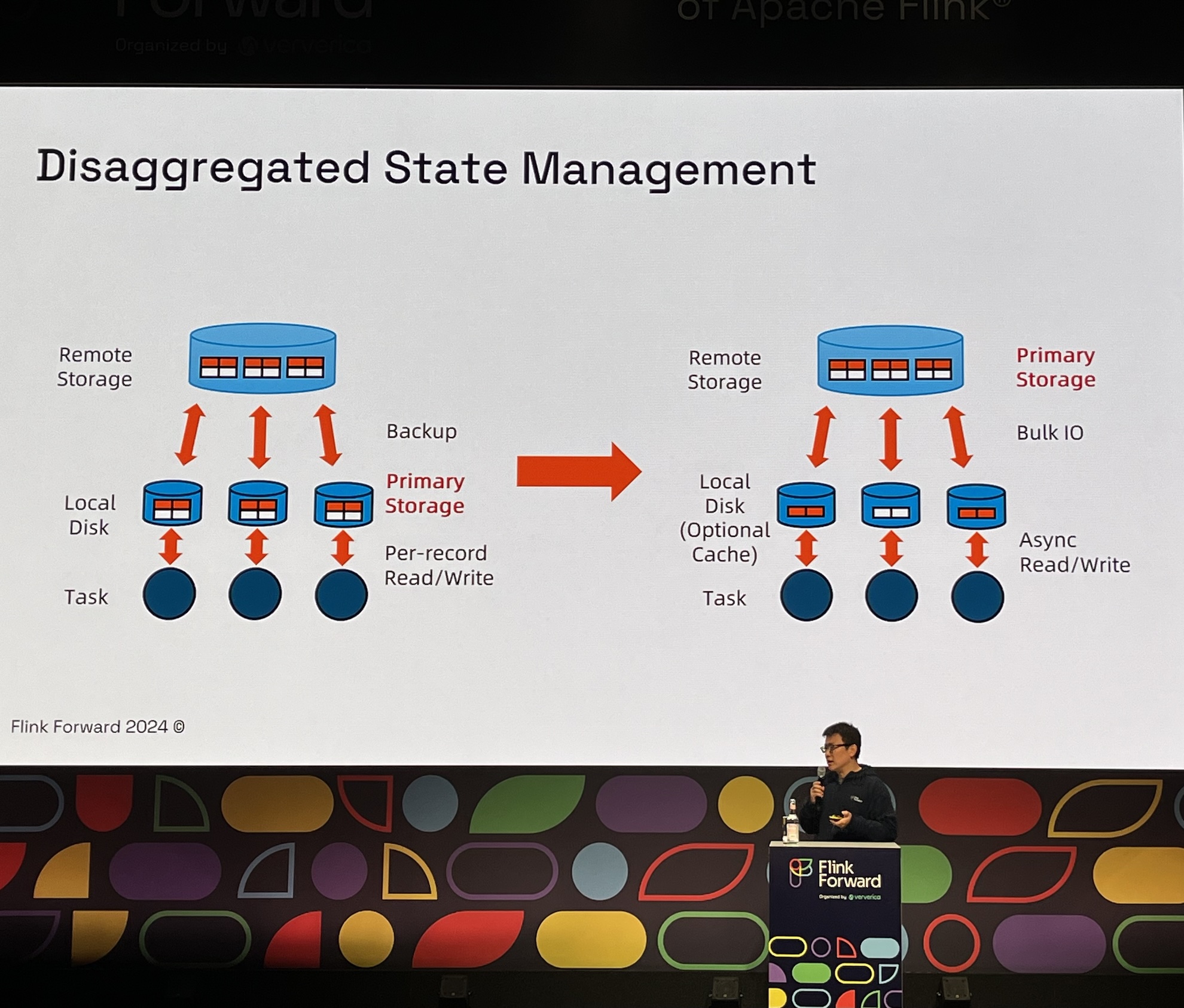
- Disaggregated state storage: Goodbye RocksDB
- External shuffle service: Welcome Apache Celeborn
- Streaming Lakehouse: An enabler for unified batch and streaming in an innovative way
- Breaking changes: While it’s unfortunate that the Scala API is deprecated, there’s a new extension available: Flink Scala API.
- PMC members mentioned that they’re going to modernize the Java Streaming API soon. It’s the oldest and hardest-to-maintain part of the Flink API.

Flink autoscaling: A year in review - performance, challenges and innovations
- Autoscaling example, simplified but self-explanatory.
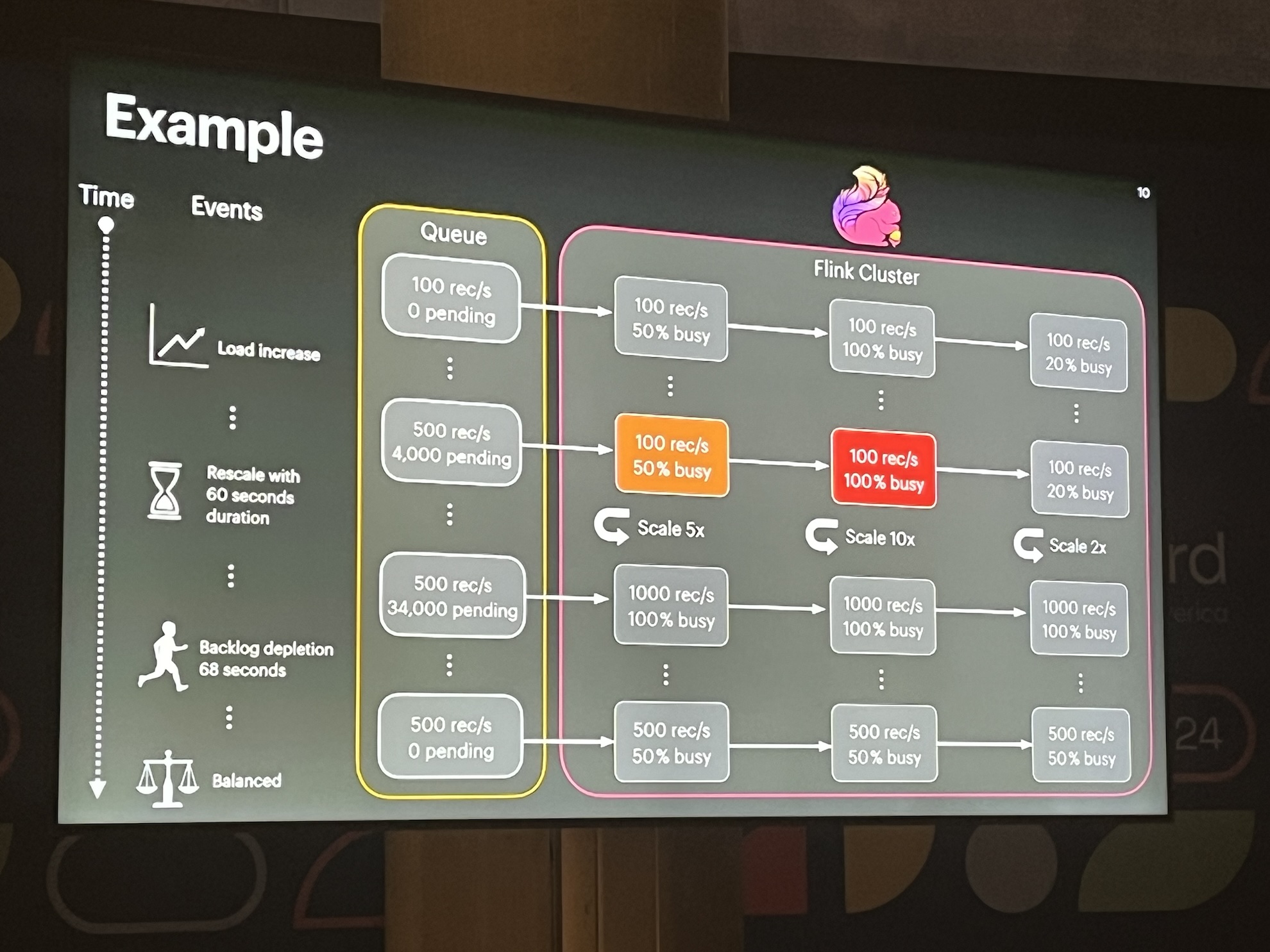
- Challenges: Unfortunately, the speaker struggled with time management and couldn’t delve into the details. The key lesson for me: don’t scale up if there is no effect of scaling. Dataflow engineering team - can you hear me?

- Memory management in Flink, for me looks like a configuration and tuning nightmare. Flink autoscaling should help, see: FLIP-271.
Scaling Flink in the real world: Insights from running Flink for five years at Stripe
- The best session of the first day, in my opinion!
- I’m sure that Ben Augarten from Stripe knows how to manage Flink clusters and jobs at scale.

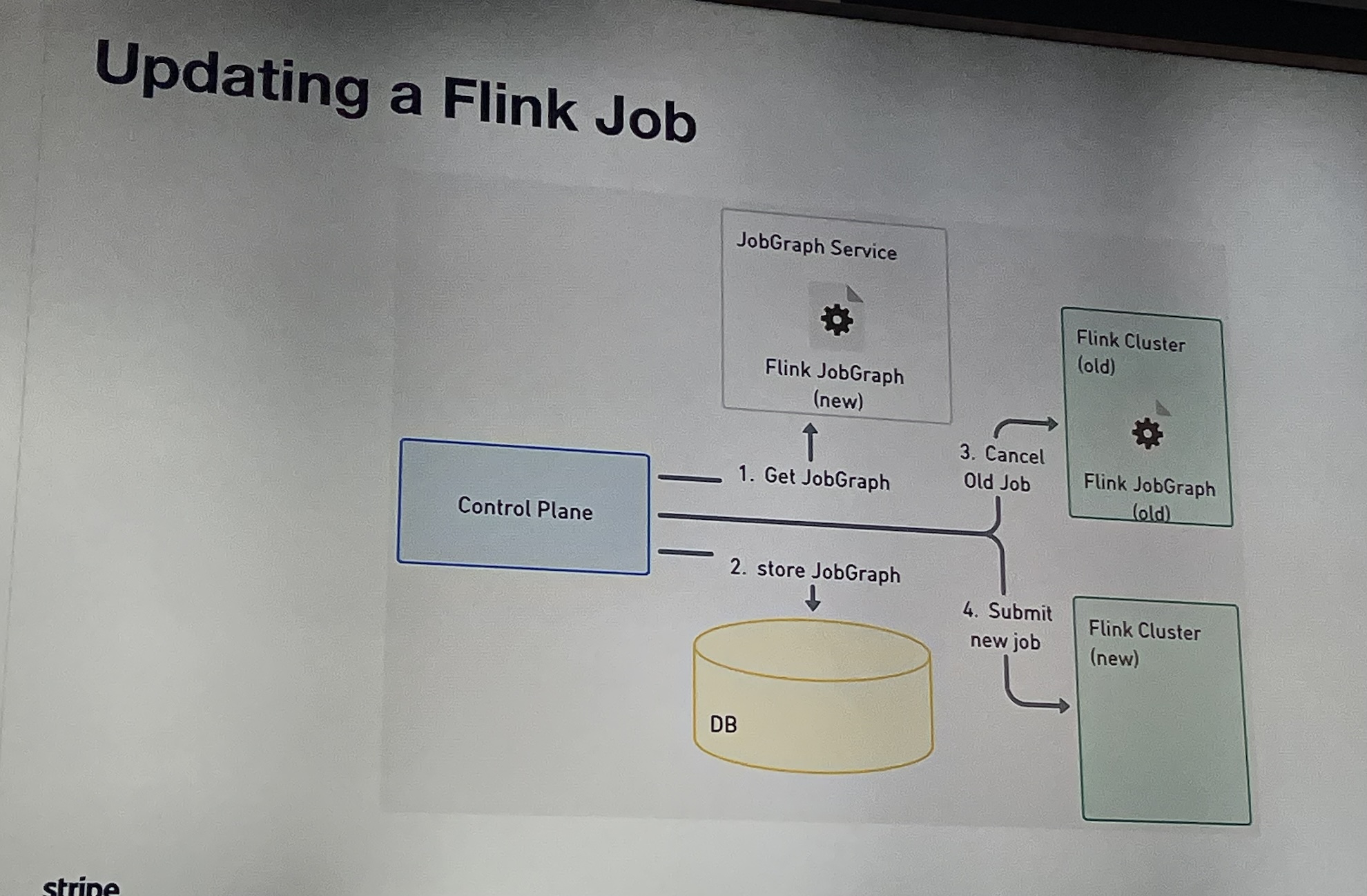
- With tight SLOs, there isn’t time for manual operations. If a job fails, roll back using the previously saved job graph. How do you decide if a job fails in a generic way? You should listen to the session.
- Use a proxy in front of the Kafka cluster to prevent jobs from getting stuck if a Kafka partition leader becomes unavailable. See: How Stripe keeps Kafka highly available across the globe
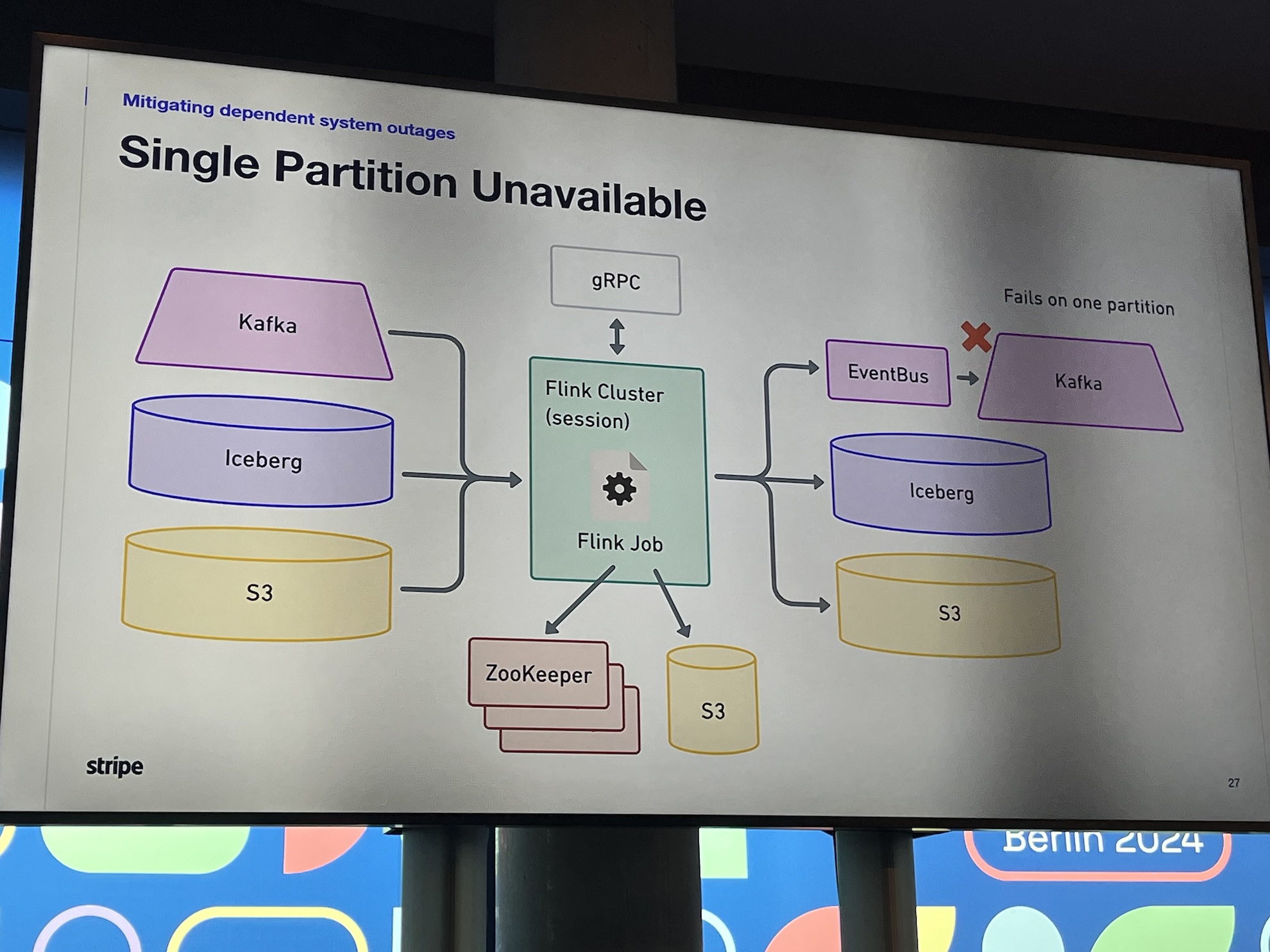
- Shared Zookeepers and shared Flink clusters can lead to issues with noisy neighbors and the propagation of failures. Extra operational costs are worth it to support system stability and performance.
Visually diagnosing operator state problems
- How to track the flow of data and identify where things go wrong?
- Can you inspect each late data record and figure out why it was late?
- Do you want to know what your state is before and after each step in your job?
- See also The Murky Waters of Debugging in Apache Flink: Is it a Black Box?
- Excellent logo, isn’t it?
Zero interference and resource congestion in Flink clusters with Kafka data sources
- Another session focused on current Kafka limitations
- Mitigation strategies for noisy neighbors in Kafka: quotas and cluster mirroring
- Introducing WarpStream: Confluent has acquired WarpStream
- Stateless, leaderless brokers
- Using object storage for state management: expect higher latency, but it should be acceptable for most use cases
From Apache Flink to Restate - Event processing for analytics and Transactions
- A new business idea from one of the Flink founders: shift the focus from analytical to transactional processing.
- Apply resilience and consistency lessons learned from building Flink to distributed transactional, RPC-based applications.

- In simple terms, it resembles an orchestrated Saga pattern
- Durable and reliable async/await
- See Why we built Restate

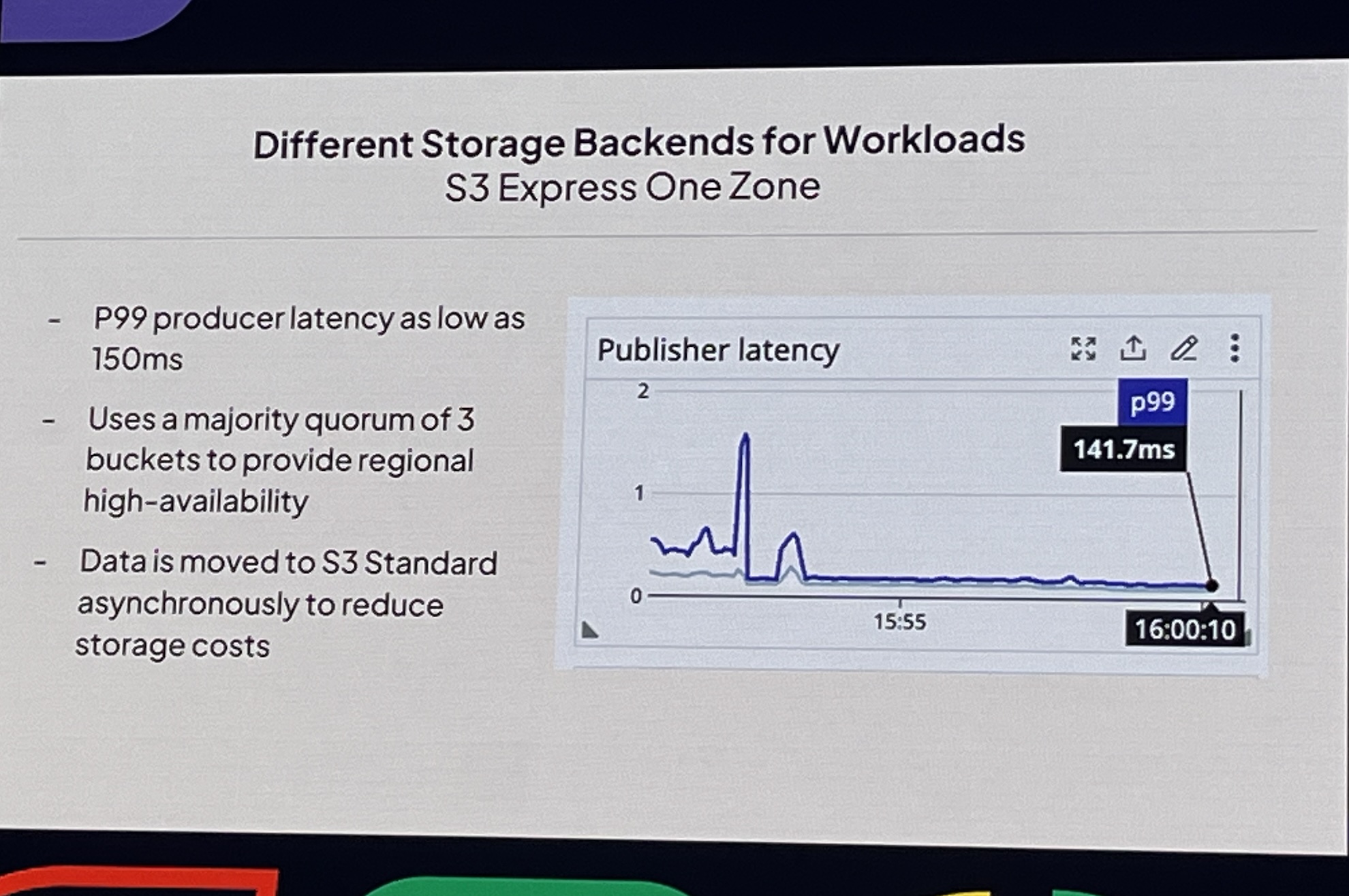
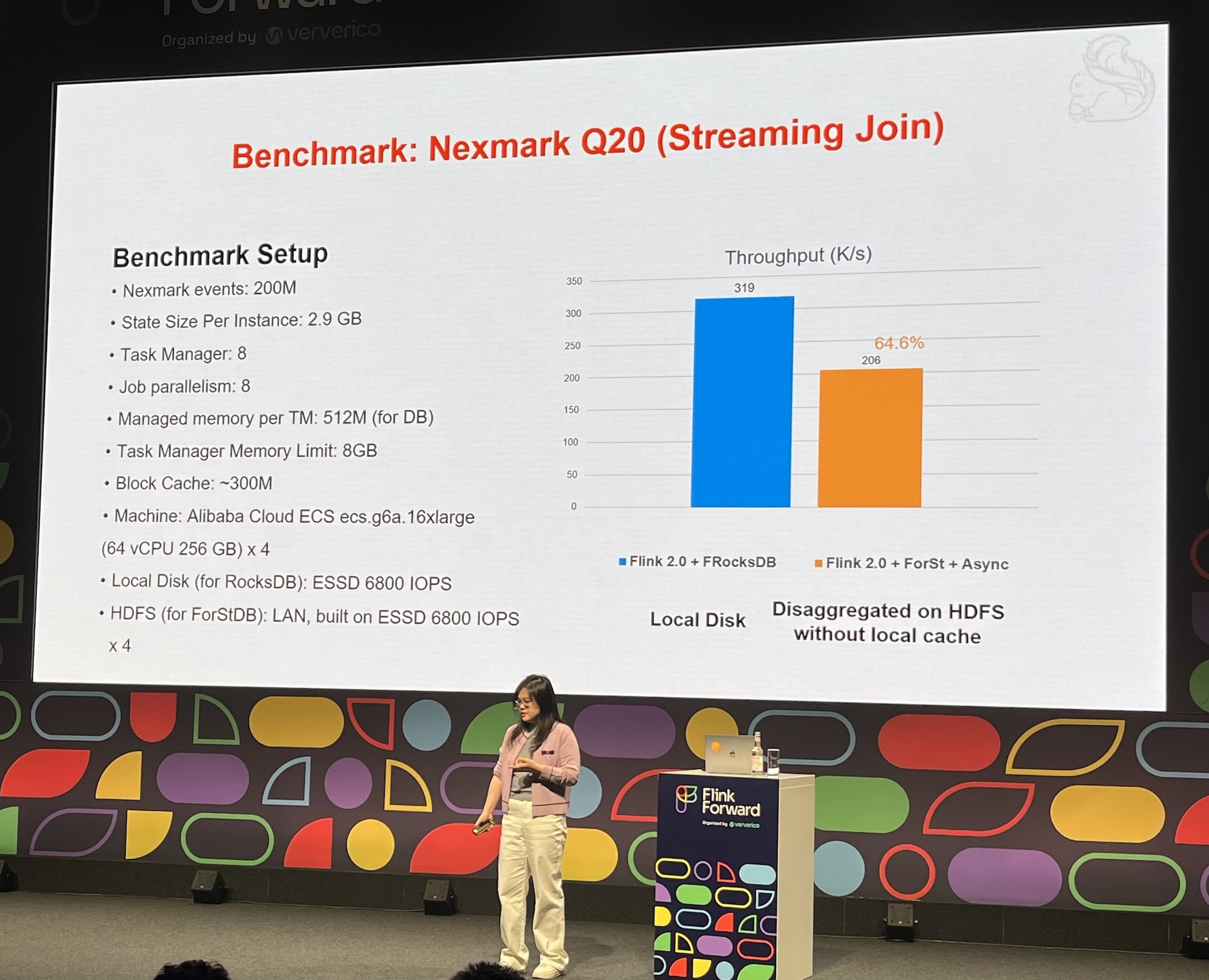
Enabling Flink’s Cloud-Native Future: Introducing ForSt DB in Flink 2.0
- The problem, local state doesn’t fit cloud native architecture.

- ForSt (for streaming) DB architecture

- Performance dropped 100x when RocksDB was replaced with object store as is.
- The new async API requires changes in all Flink operators!
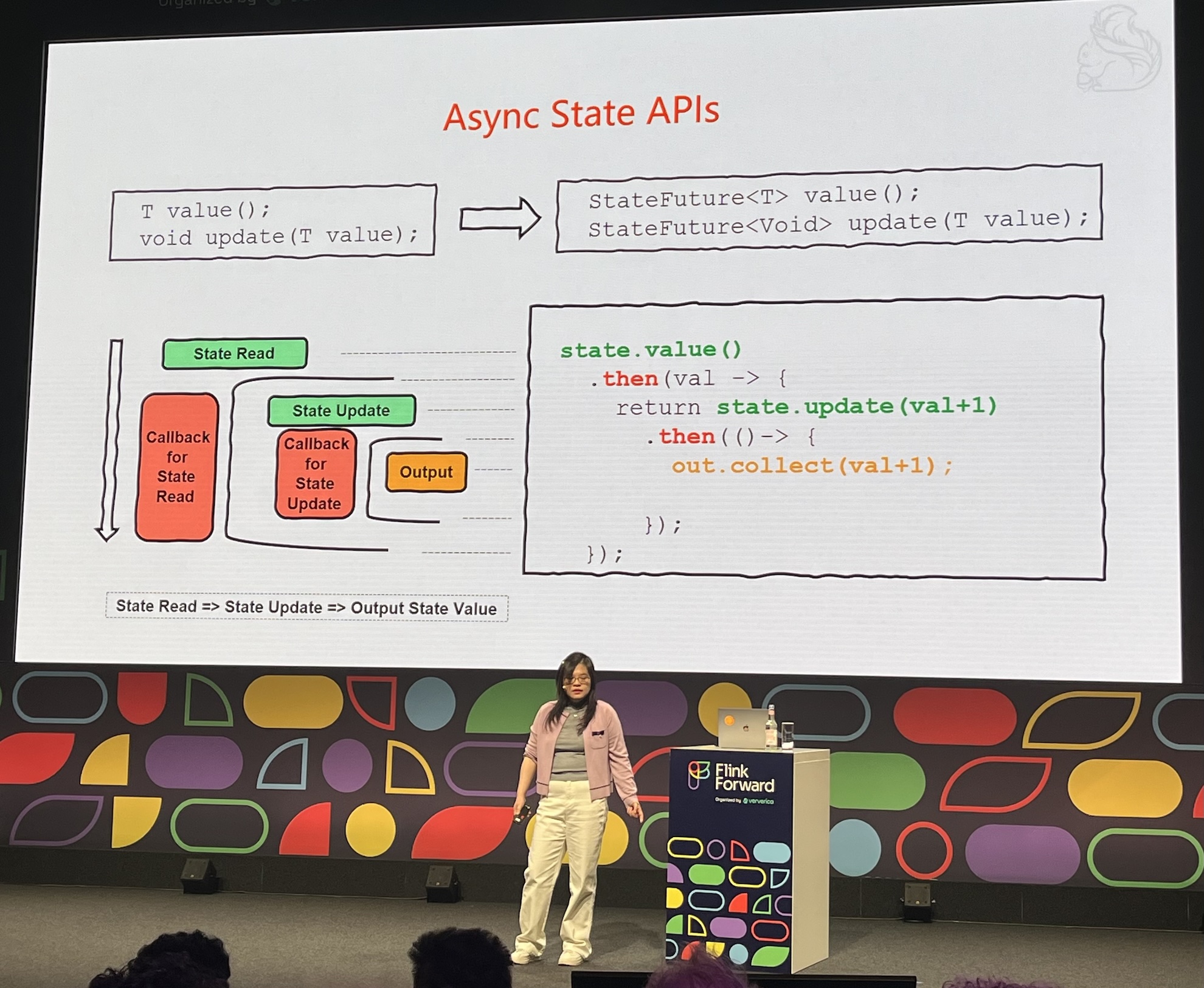
- Asynchronous improves performance but introduces new challenge: ordering
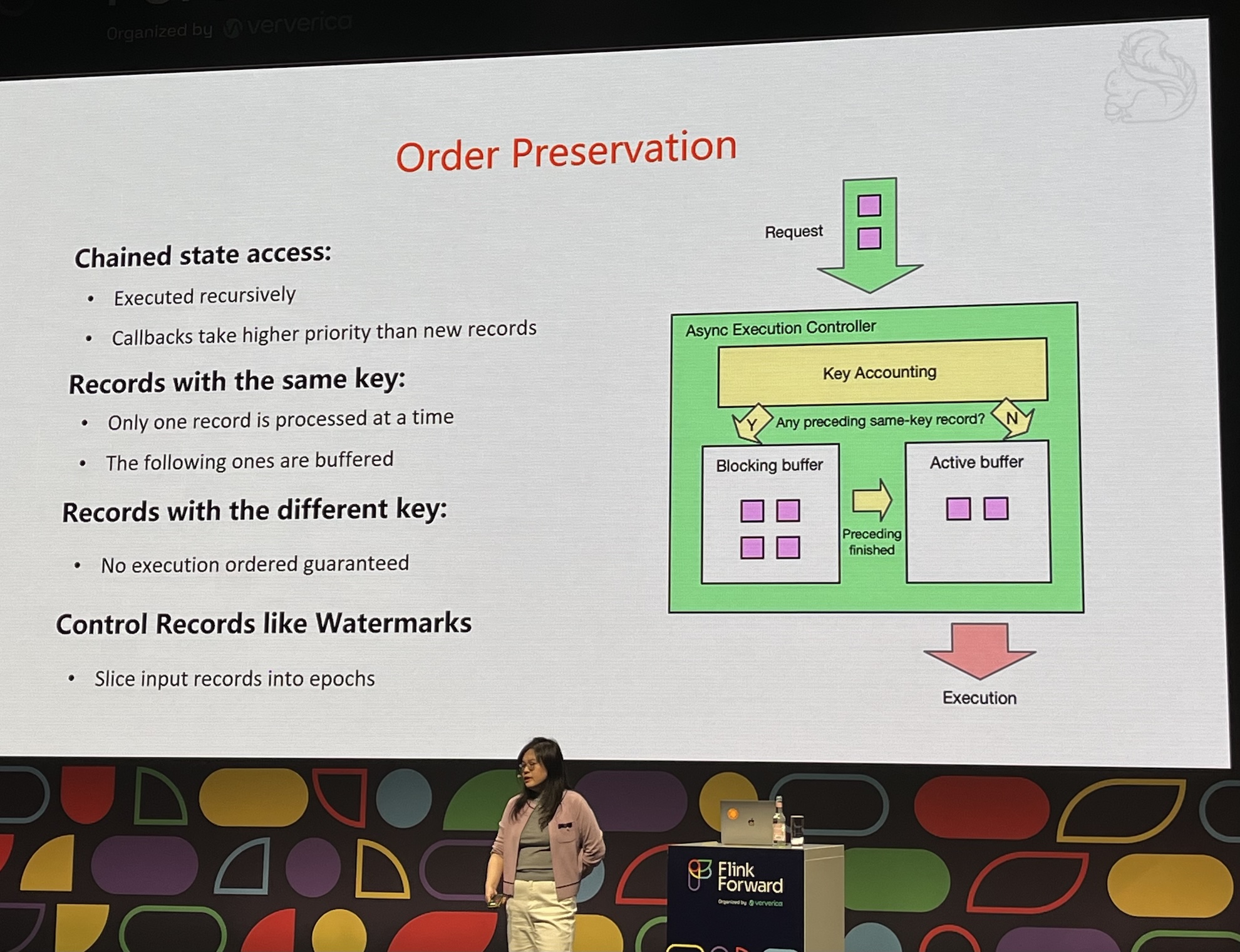
- Slower than local RocksDB, but performance looks promising
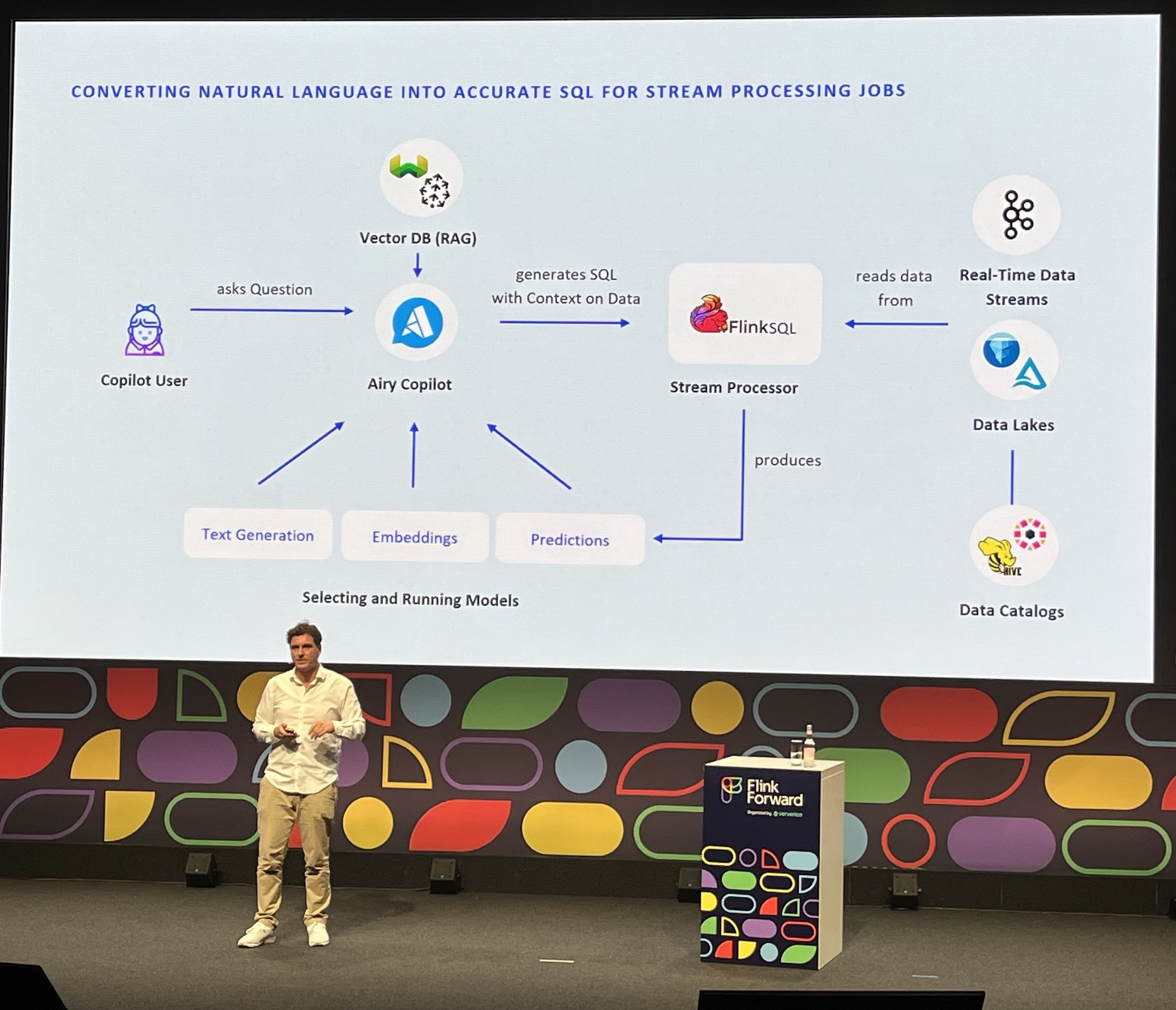
Building Copilots with Flink SQL, LLMs and vector databases
- The most entertaining session of the conference, in my opinion
- How to adopt real-time analysis for non-technical users?
- Steffen Hoellinger invited us to conduct a POC together with Airy
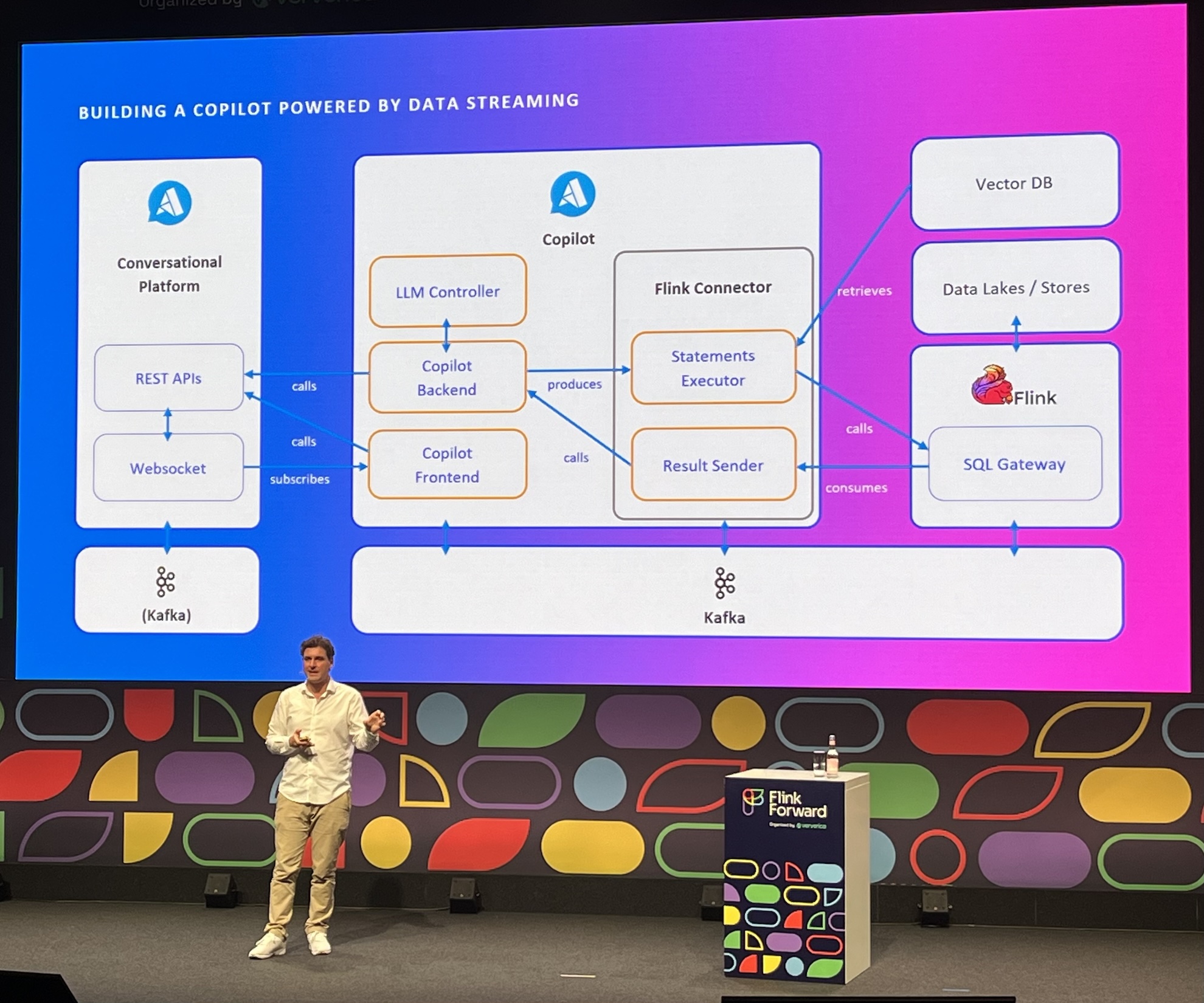
- Hmm, some technical knowledge is still required 😀
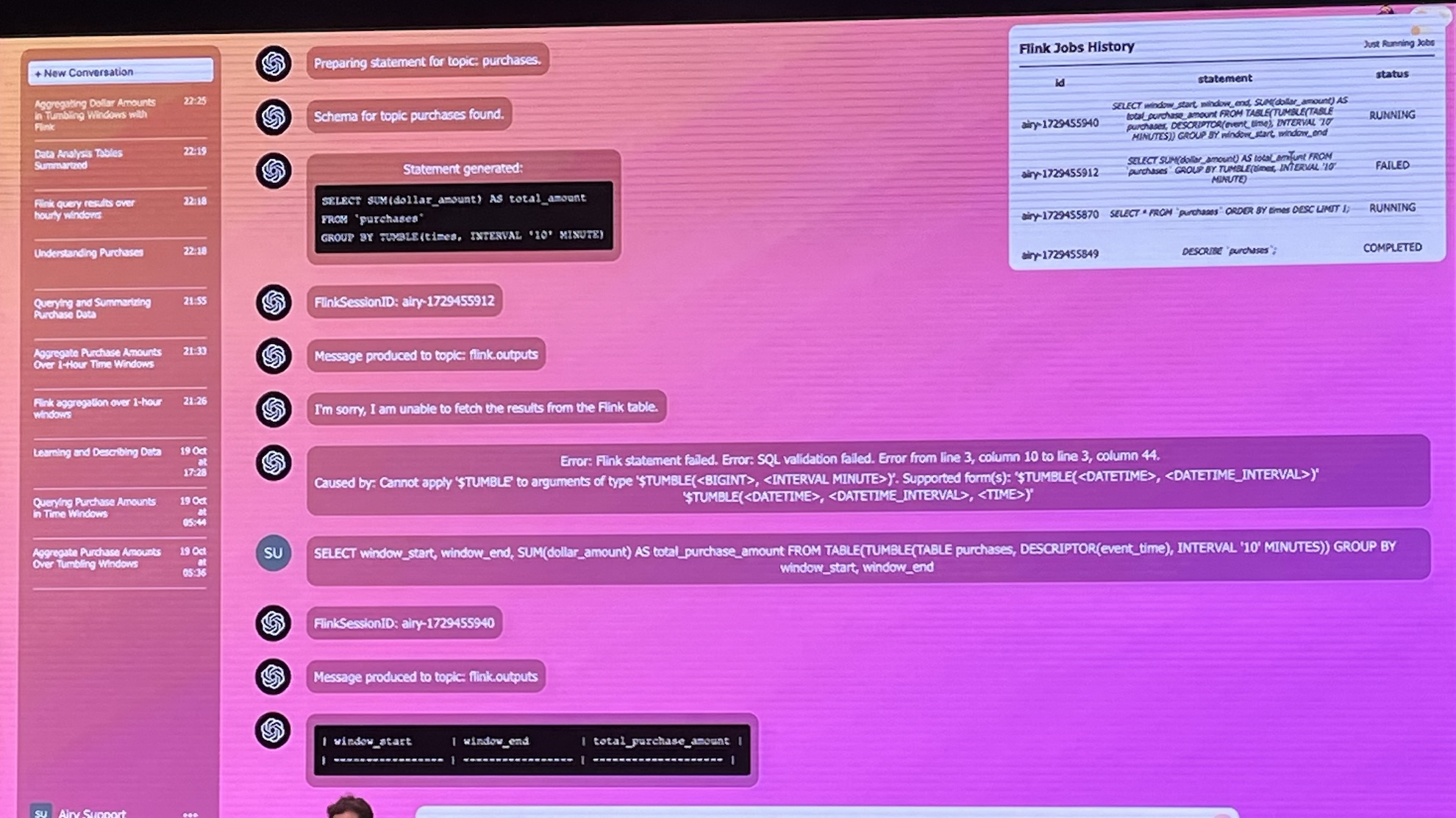
- Key lesson: context is much more important than model
- Keep small workspaces to avoid hallucinations
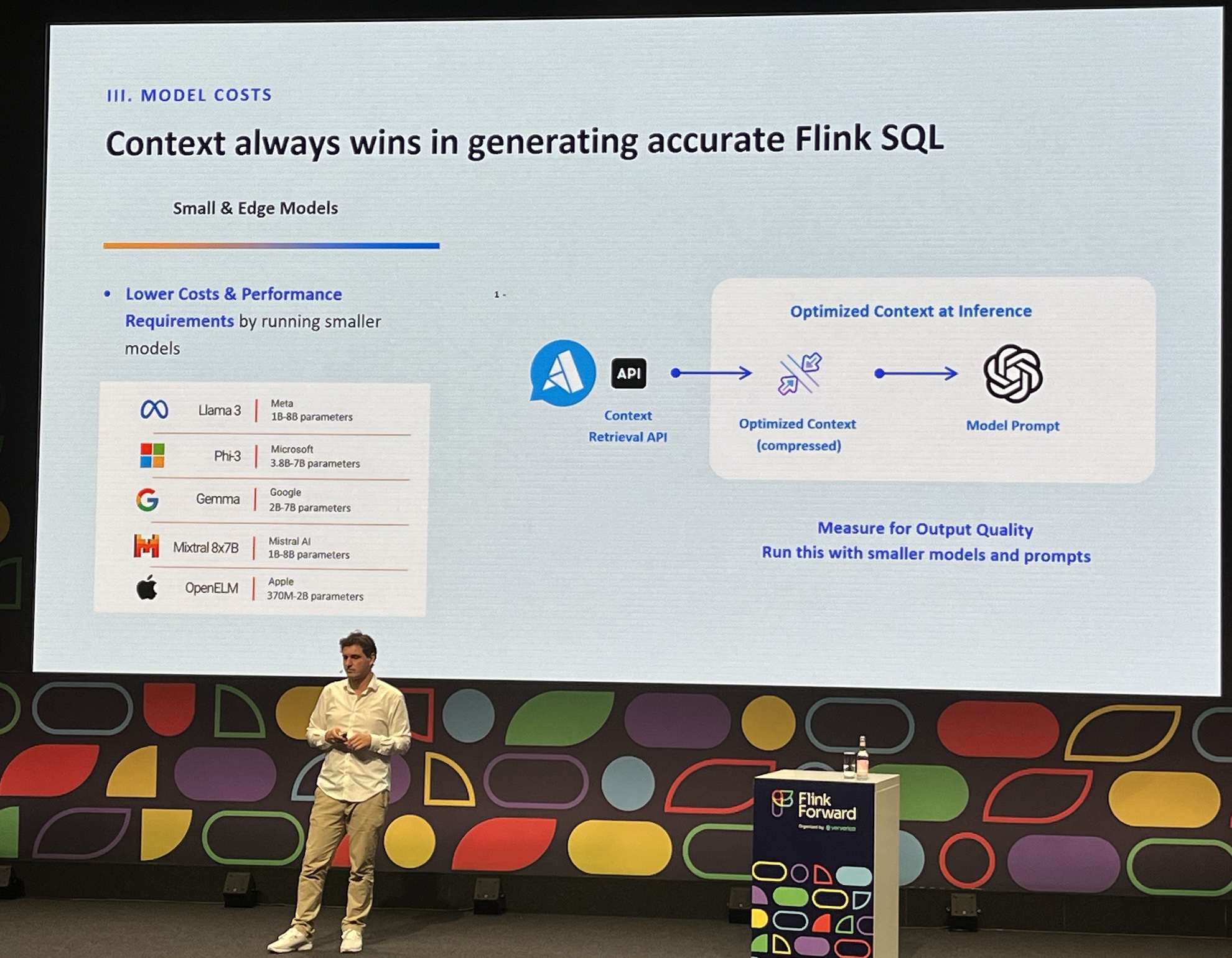
- Flink SQL ML models, see: FLIP-437
Materialized Table - Making Your Data Pipeline Easier
- The most eye opening session
- Batch, incremental and real-time unification
- Backfill

- Freshness vs Cost
- Apply
SET FRESHNESS = INTERVAL 1 HOURand framework will do the rest - Support for most SQL queries (without
ORDER BYcause)
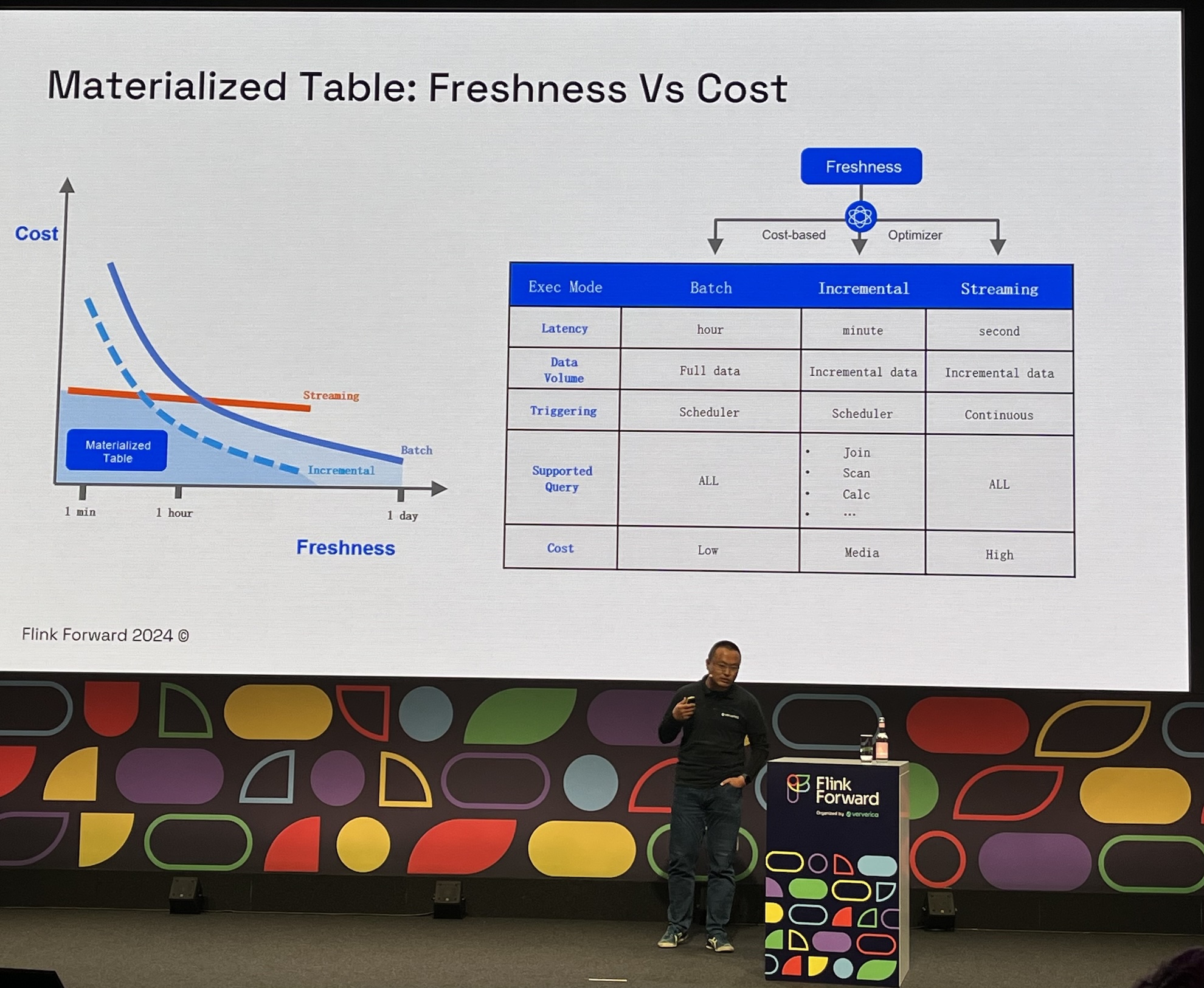
- Cool demo, materialized view freshness changed, Flink jobs rescheduled and BI dashboard updated in-place. Yet another scenario for backfill.
- Community version coming soon, see FLIP-435.
Event tracing
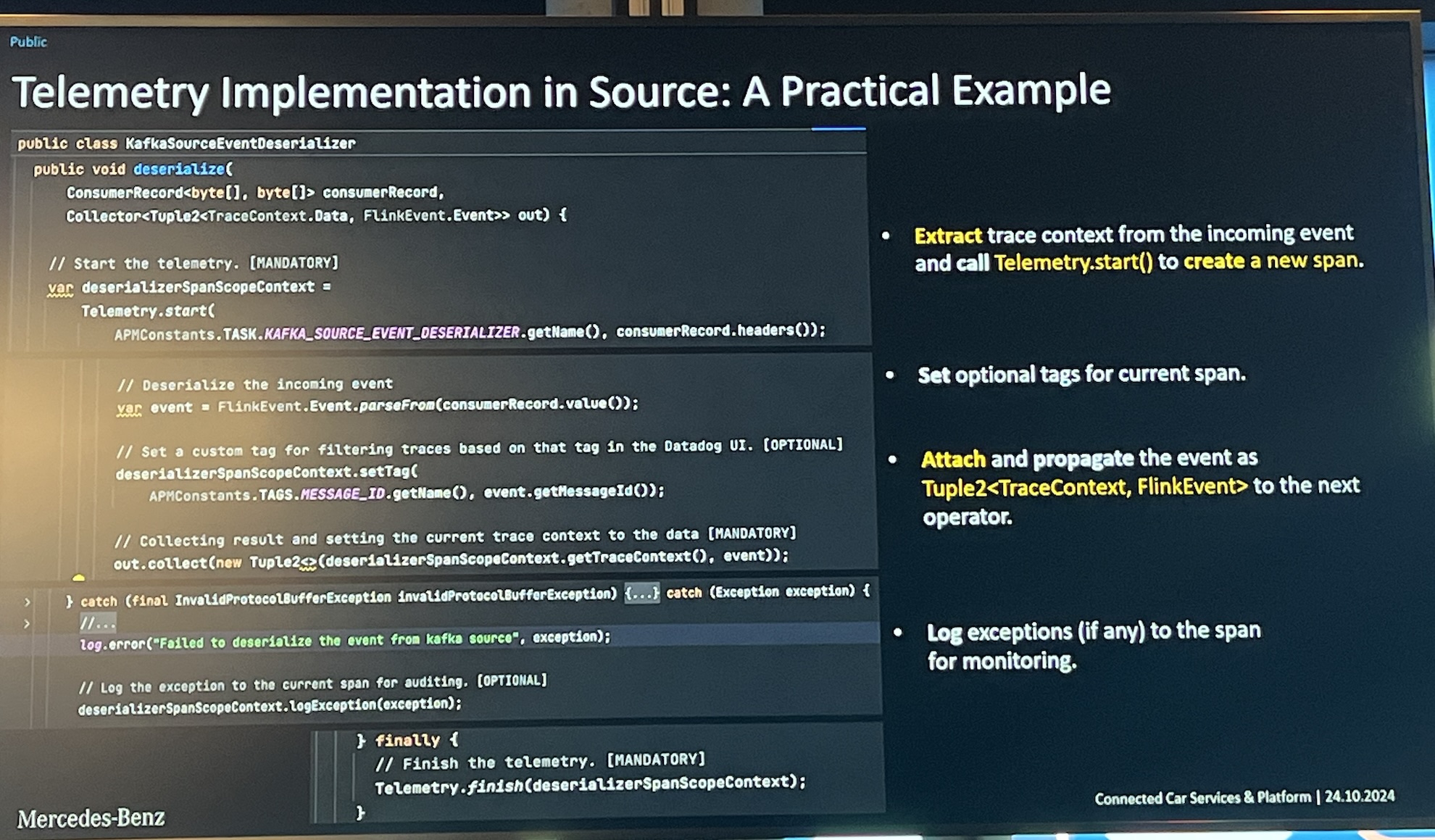
- Session based on IoT vehicle data in Mercedes-Benz.
- Apply OpenTelemetry for real-time data pipelines
- Tracing events sampling to avoid negative performance impact
- Kafka sources: extract tracing from headers
- Flink steps: attach spans to all events
- Kafka sinks: add tracing to headers
- In-summary: a lot of extra work
Summary
Attending the conference was a valuable experience, offering deep insights into the latest developments in Apache Flink. Here are my key takeaways:
- Listening to sessions about the challenges of Flink deployment and operations from the trenches made me appreciate the simplicity of Dataflow even more.
- I now believe in the potential of truly unified batch and streaming processing.
FLIP-435 and the streaming lakehouse give hope that
SET FRESHNESScould switch processing modes from batch, through incremental, to real-time. - For high adoption of real-time analytics, consider using GenAI to hide the underlying data pipelines complexity.
- My general impression is that Kafka’s limitations in the cloud-native era have been confirmed.

Comments